游戏研发场景题
战争迷雾
- 大量移动单位和大视野不动单位
这个用个循环暴力计算显然不现实, 除非你地图很小. 所以, 优化思路就是针对移动的单位重新计算, 针对不动的单位只算一次
首先, 我们可以用坐标(X,Y)和视野半径(R)三个值确定出一个唯一值K代表一个提供视野的单位U
对于每帧新加入(K当前不存在)的U, 定义其生命周期L=MAX. 其余的就对U的L进行递减
移除L<=0的U. 针对于L=MAX的, 计算其可见的格子, 如果可见, 则格子的计数C加1
每个格子的可见计数C>0的表示可见, 否则就是不可见, 然后更新到纹理上
对于0<L<MAX的单位U全部不用计算, 所以不动的单位就不用更新
- 预计算FOV
如果视野阻挡不会变化的话, 可以针对每个点计算其最大视野范围的可见性信息, 缓存起来
如果用1bit表示每个格子, 最大视野范围20, 地图大小256x256个格子的话, 所需要的内存空间为41x41x256x256bit=13.13MB, 如果再剔除掉视野阻挡内的点, 应该更小
- 平滑
加了一个速度适中的渐变动画效果而已。需要消除/添加阴影时,不去瞬间切换遮罩物透明度,而是触发一个渐变过程,使玩家产生错觉。
热更新的方式
1.使用基于lua的ulua技术,让游戏部分ui或者部分逻辑模块使用lua脚本编写,这样可维护性强,易于扩展。(准则:动态特性适合用来做游戏UI)
2.使用C#Assembly 的反射技术( class.GetType.Assembly & calss.GetType),正如前面所说,安卓适合,苹果不适合,这样就满足不了发布双版本的需求。
3.最后一种就是C#中的light技术。
排行榜
redis有序集合->字典+跳表
如果人还是太多->分桶
网格法
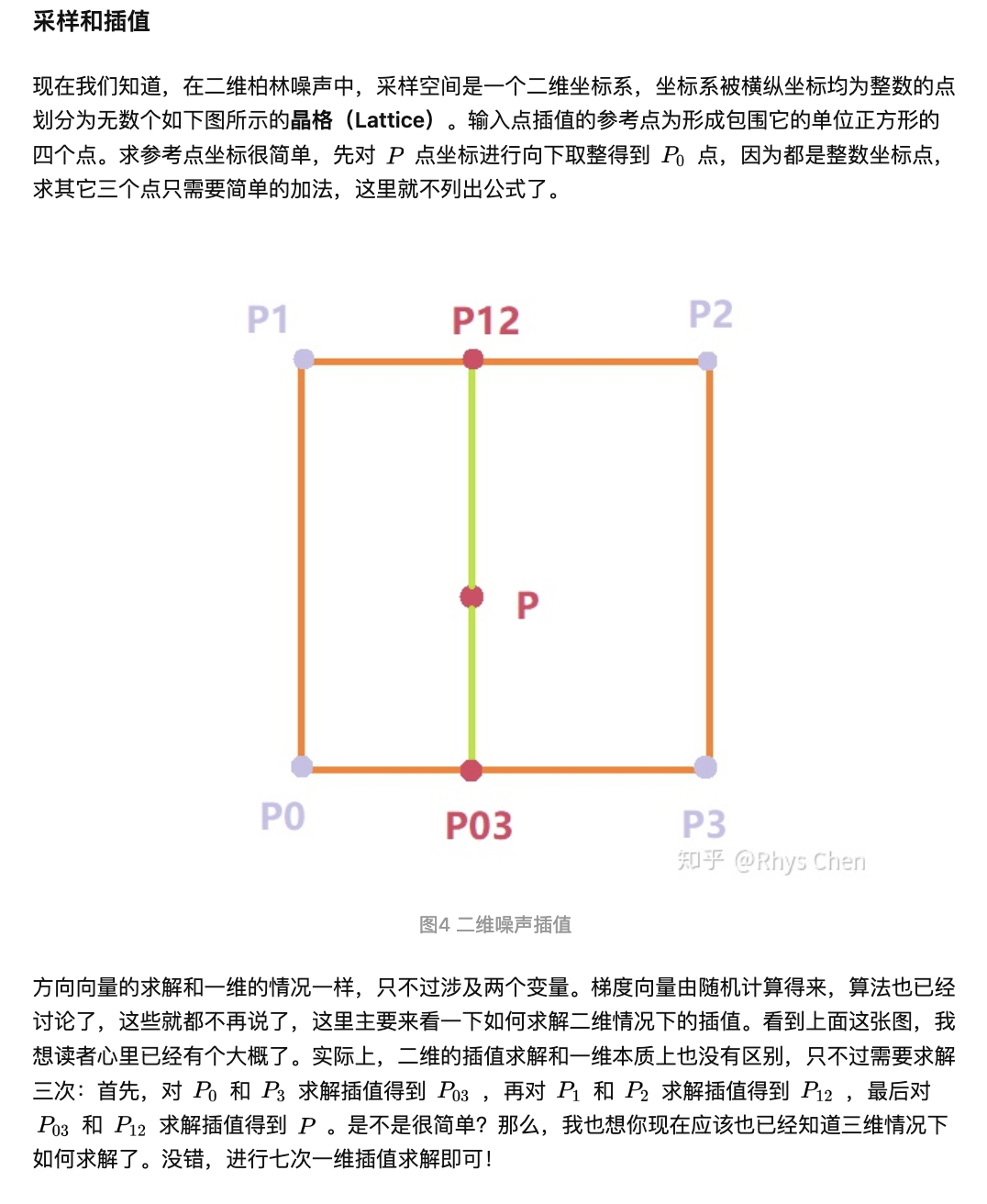
网格,顾名思义就是把游戏场景划分为一个个格子,如图所示,2D的情况下使用的是一个二维数组,图中的白块处于第6行第6列(左下作为起点),那么它应该存入[5,5]的索引中。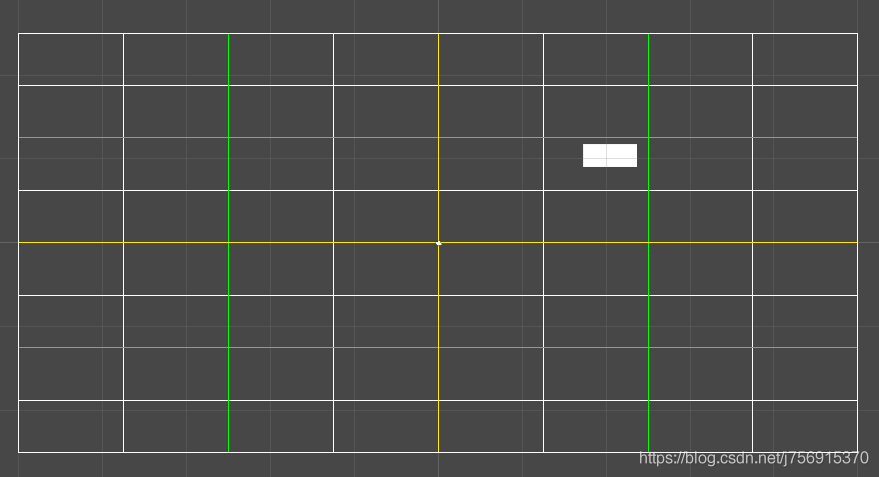
如果物体跟网格线交叉了,如下图,物体没有完全处于网格内,那么它应该存储在和它交叉的所有网格:[4,4],[4,5],[5,4],[5,5]。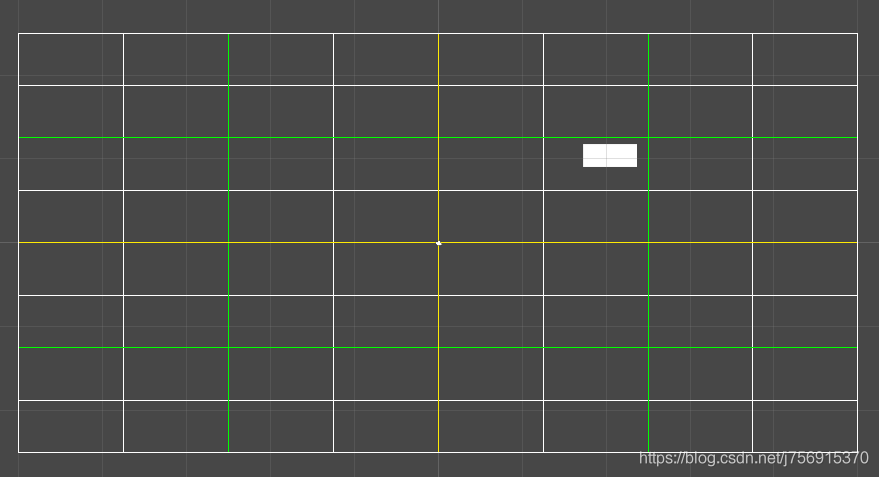
当查询时,只要找到物体所在的网格,拿出网格内的所有其他物体挨个遍历即可。
到这里,我们可以总结出网格法的优缺点:
- 物体插入时很快,只有O(1)复杂度
- 物体可以很方便地动态更新自己在网格中的位置
- 对于跨多个网格的物体,需要占用更多的空间来存储
八叉树
八叉树(octree)是三维空间划分的数据结构之一,它用于加速空间查询,例如在游戏中
邻近查询(proximity query),如查询玩家角色某半径范围内的敌方NPC。
碰撞检测的粗略阶段(broad phase),找出潜在可能碰撞的物体对。
简单来说,八叉树的空间划分方式是,把一个立方体分割为八个小立法体,然后递归地分割小立方体。
四/八叉树有多种变种,先谈一个简化的情况,就是假设所有物体是一个点,这样比较容易理解。把每点放到正方形空间里,若该正方形含有超过一个点,就把该正方式分割,直至每个小正方形(叶节点)仅含有一个点,就可以得出以下的分割结果:
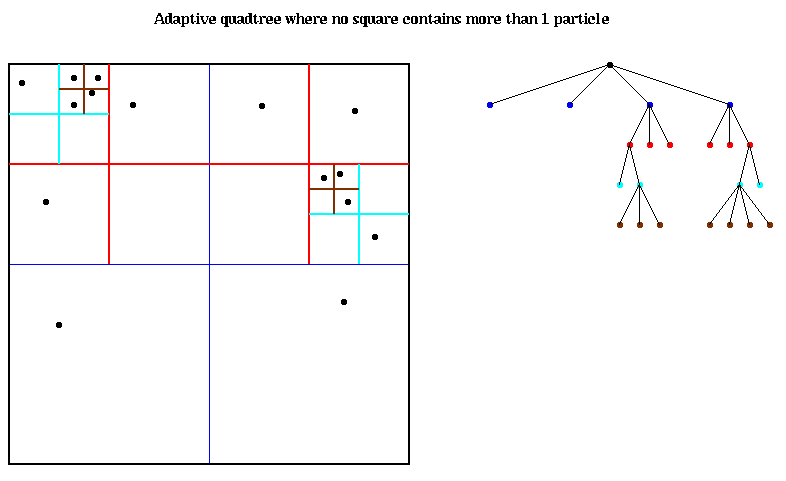
问题:当一个物体超出划分范围/正好在边界上:
1.所有与物体相交的子节点都引用这个物体
2.令非叶子结点也能放置物体(小正方体装不下就用它的上一级较大的那个正方体来装)
第一种方法的范围比较精确,但如果物体的大小相差很大,大体积的物体便需要被大量小范围的叶节点引用,而且管理上也会很麻烦。第二种做法是较常用的方法。然而,第二种方法的范围可能非常大,例如物体刚好在场景的中心,即使是一个体积很小的物体,都只能放于根节点里。
另一个问题在于动态更新。
想想看,如果四叉树内的物体每帧位置都在变化,四叉树应该如何更新?每帧都重建四叉树?那肯定不行,太费时间了。 首先需要找对旧位置所在的节点 ,把节点里存的物体列表中删掉当前这个在移动的物体,删掉后还要考虑已经分裂的子四叉树是不是需要删除,然后对于新位置的处理,这个就比较好办,按照插入时的逻辑就可以了。
解决:松散四/八叉树(稍微扩大正方体(包围盒))
松散八叉树的“松散”是指调整节点的包围体大小,“放松”包围立方体,但是同时节点的层次和节点的中心不变。在松散八叉树中,包围立方体边长的计算公式修改为:
松散四叉树/八叉树中,出口边界比入口边界要宽些(虽然各节点的出口边界也会发生部分重叠),从而使节点不容易越过出口边界,减少了物体切换节点的次数。
问题在于如何定义出口边界的长度。因为太短会退化成正常四叉树/八叉树,太长又可能会导致节点存储冗余的物体。经过前人的实验表明出口边界长度为入口边界2倍最佳。
当出口范围是入口范围2倍的时候,松散四叉树会多一个神奇的特性:
如果一个AABB大小小于一个四叉树节点的入口范围,那么只要这个AABB的中心点在入口范围内,那么这个AABB一定包含在出口范围内
松散四叉树结合网格法
我们都知道,当四叉树节点里的物体数量到达一个阈值时,我们会分裂四叉树,如果要支持动态更新,分裂后的四叉树可能还要删除。那么如果我们一上来就把四叉树全部分裂完呢?不管节点里有没有物体都不删除四叉树节点呢?这样的话这个四叉树就会跟网格很像。
有了松散四叉树配合网格法,我们能够快速找到一个物体应该插入的位置。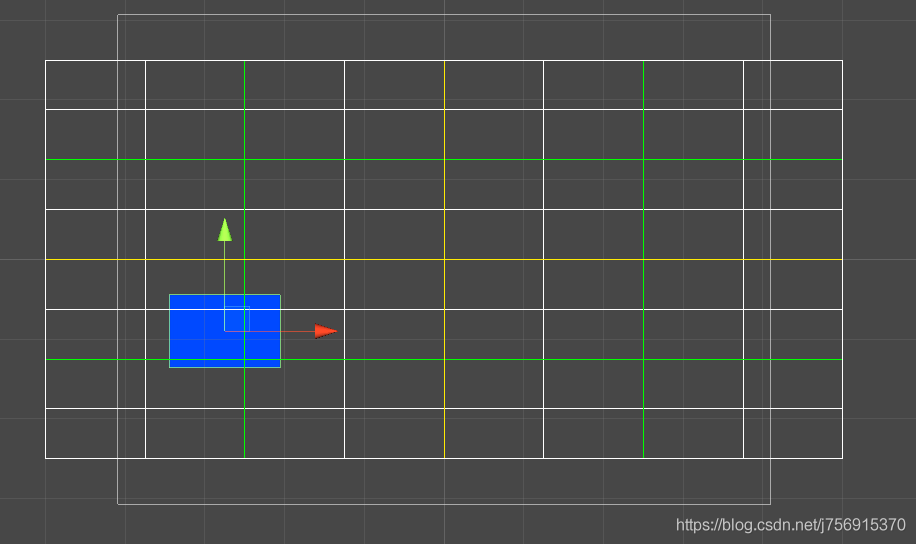
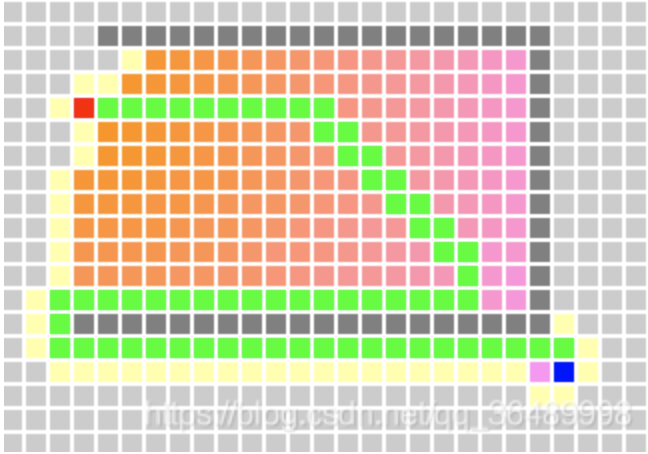
如图,我们把一个区域分成了三层的网格,图中黄色线代表第一层的网格,绿色线代表第二层的网格,白色线代表第三层的网格。我们可以发现,蓝色方块的大小大于第三层的网格(只有宽、高其中之一比网格大就算),小于第二层的网格,所以它最终应该放在第二层的四叉树上。
接着我们来看它的中心点的位置,我们使用的是2倍的松散四叉树,所以中心点在哪个节点,物体就在哪个节点。通过观察我们可以发现,蓝色方块的位置在第一层四叉树的左下节点,第二层四叉树的左上节点。
我们用一个2x2的2维数组来表示四叉树的四个子节点,用行和列表示索引,左下是[0,0],左上[1,0],右下是[0,1],右上是[1,1]。蓝色方块的位置就是根节点的[0,0]子节点的[1,0]子节点。
发现没有,使用松散四叉树结合网格法,可以快速得出一个物体要插入的位置,从原来的O(logn)复杂度变成O(1)复杂度。(可能有人会疑惑为何原先是logn复杂度,因为传统四叉树的插入是一种二分查找算法。二分查找的复杂度就是logn。二分查找是两半取其一不断循环,四叉树插入是四半取其一不断循环,本质一样。)
游戏地形生成
**噪声(Noise)**实际上就是一个随机数生成器,当然,这是一种伪随机(现实世界中的真随机在计算机中不存在)。我们所看到的那些黑白噪声图,实际上是随机数映射到0和1之间产生的灰度图。随机本身就是不同,那为什么还需要不同的随机?
普通噪声(随机数生成器)的问题在于,它实在太过于随机,毫无规律可言(如图1所示)。(太突兀、嘈杂、刺眼)

柏林噪声:平滑的、均匀性的噪声、随机值一部分取决于周边元素
https://zhuanlan.zhihu.com/p/206271895
柏林噪声基于随机,并在此基础上利用缓动曲线进行平滑插值,使得最终得到噪声效果更加趋于自然。基于不同的采样空间,柏林噪声可以分为一维、二维和三维。维度不同,但其基本原理是相同,都主要经过以下三个步骤:
- 初始化相关数据,包括**排列表(Permutation Table)和梯度表(Gradient Table)**等。
- 建立采样空间。对于一维柏林噪声,采样空间为一个一维的坐标轴,轴上整数坐标位置均有一个点。而对应二维柏林噪声,采样空间为一个二维坐标系,坐标系中横纵坐标为整数的地方均有一点。三维柏林噪声同理。
- 对于不同类型的噪声,对采样点在不同空间中,根据最近的参考点的梯度和缓动曲线进行插值计算。
噪声细节函数
- 多少层柏林噪声
- 这些柏林噪声怎么结合在一起
same seed->same result
高度图:2D的只有高度的图用来表示3D
三角形网格
如果对整张图使用二维柏林噪声,那整张图的地形都差不多,如何形成又有山坡又有平原的地形?对地形再加一维柏林噪声。(甚至可以给湿度,温度加柏林噪声)
初始化
在初始化排列表和梯度表之前,我们先了解一下它们的作用。排列表是一个乱序存放一系列索引值的表,而梯度表是一个存放了一系列随机梯度值的表,两者都具有很强的随机性。在决定一个点的梯度时,需要结合哈希函数,以点的坐标为参数,利用所得的值作为索引,去排列表中取对应的值。所取得的排列表中的值,就是该点在梯度表中对应梯度值的索引。这样解释可能会有些让人摸不着头脑,我们来看一段伪代码。
1 | // 排列表 |
在一维柏林噪声中,各个整点的梯度就是斜率,所以我们可以不依赖梯度表,将排列表中所取到值直接作为梯度即可。因为排列表中的值是乱序的,所以有良好的随机性,且对于同样的输入,它的输出都相同,伪随机性也得以保留。在***Ken Perlin***的经典噪声算法中,使用的排列表是由数字0到255散列组成的。
1 | // Language: Processing |

柏林噪声的生成算法其实并没有那么难,主要经历以下三个步骤:
- 对排列表和梯度表进行初始化,梯度表可以不必随机生成,选择单位圆(球)上的对称的梯度向量也可。一维向量可以不用梯度表,直接用排列表中的值进行映射也能达到效果。
- 对于噪声图上的像素,找到它在晶格上对应的一点,并求出它的参考点的坐标。在一维情况下,参考点为两侧最近的整数点;二维情况下,参考点为组成包围该点的单位正方体的四个点;三维情况下,参考点为组成包围该点的单位立方体的八个点。需要注意的一点是,晶格必须与图片对齐且完全覆盖,否则坐标映射会很麻烦。
- 根据参考点的方向向量和梯度向量,并结合缓动曲线,求解最终的灰度值。一维噪声只需一次插值,二维需要三次插值,三维需要七次插值,呈指数增长,所以算法的时间复杂度是 $O(2^n)$
不是存储世界,而是存储建造世界的方式
Minecraft生成
individual chunk:16x16x256
indvidual chunk整合在一起->the whole world
一开始生成的:spawn chunk
生成一个chunk的步骤
1.生成高度图(height map generation)仅由石头 水 和空气构成
2.矿物层(ore stage)
3.表层被替换成泥土或者沙
3.雕刻层,山洞 cave ravines canyons
4.生成结构(树,村庄)还有生物
chunk是怎么连接成为一个顺滑的世界的?
约40层噪声实现:不同生物群落以及在什么地形下该生成怎样的雕刻层,表层
每一个世界都是从整片海洋开始的
每一个群落都有一个编号,而海洋是0
第一层噪音层是海洋
不同的噪声层叠加,陆地面积越来越多
每个群落都有一个温度值,温度值随着海拔升高会降低
温度取决于生物群落
温度相近的生物群落常常聚集在一起
边缘层
气候过渡
有一层是专门用来生成蘑菇岛的
生物群落变种
河流
海岸线
chunk的加载
每个区块的加载都来源于一个“加载标签”。
每个加载标签具有3个属性:加载等级,标签类型和存活时间(可选属性)。
加载等级
加载等级用于决定了这个区块中哪些游戏内容能够被运算。
加载等级的范围是0-45。只会在0-33的范围里有常规的游戏运算。加载等级45以上是不可能的。
一个区块如果获得多个加载等级,只有最小的加载等级是有效的。加载等级越小,游戏会运算更多内容。
加载等级可以分为以下有四种加载等级类型:
| 类型 | 等级 | 属性 |
|---|---|---|
| 强加载 | 31及以下 | 所有游戏内容都能够被运算。 |
| 弱加载 | 32 | 除了区块刻以及实体不会运算(例如不会移动),所有的游戏内容都正常运行。 |
| 加载边界 | 33 | 只有少部分游戏内容会正常运行(红石元件和命令方块等都不能运行)。 |
| 不可访问 | 34及以上 | 各种游戏内容都不会运算,但世界生成会在这些区块中运行。 |
等级传播
带有加载标签的区块,会相邻(8个)的区块传播加载等级。对于每张“标签”使用“flood fills”算法从“标签”的位置传播,每向外传播一次就加载等级增加1,直到达到上限45。
| 34 | 34 | 34 | 34 | 34 | 34 | 34 |
|---|---|---|---|---|---|---|
| 34 | 33 | 33 | 33 | 33 | 33 | 34 |
| 34 | 33 | 32 | 32 | 32 | 33 | 34 |
| 34 | 33 | 32 | 31 | 32 | 33 | 34 |
| 34 | 33 | 32 | 32 | 32 | 33 | 34 |
| 34 | 33 | 33 | 33 | 33 | 33 | 34 |
| 34 | 34 | 34 | 34 | 34 | 34 | 34 |
| IN | IN | IN | IN | IN | IN | IN |
|---|---|---|---|---|---|---|
| IN | BO | BO | BO | BO | BO | IN |
| IN | BO | TI | TI | TI | BO | IN |
| IN | BO | TI | ET | TI | BO | IN |
| IN | BO | TI | TI | TI | BO | IN |
| IN | BO | BO | BO | BO | BO | IN |
| IN | IN | IN | IN | IN | IN | IN |
标签类型
不同来源的标签有不同的类型,用于确定不同加载等级。
玩家
由玩家加载的标签。“玩家”标签的加载等级为31。玩家的加载范围内的区块都会获得“玩家”标签。
玩家的模拟距离会生成模拟标签,模拟标签与玩家标签不同,独立计算。
寻路算法
估价函数可以贪心的搜索更像答案的状态,减少搜索的状态数
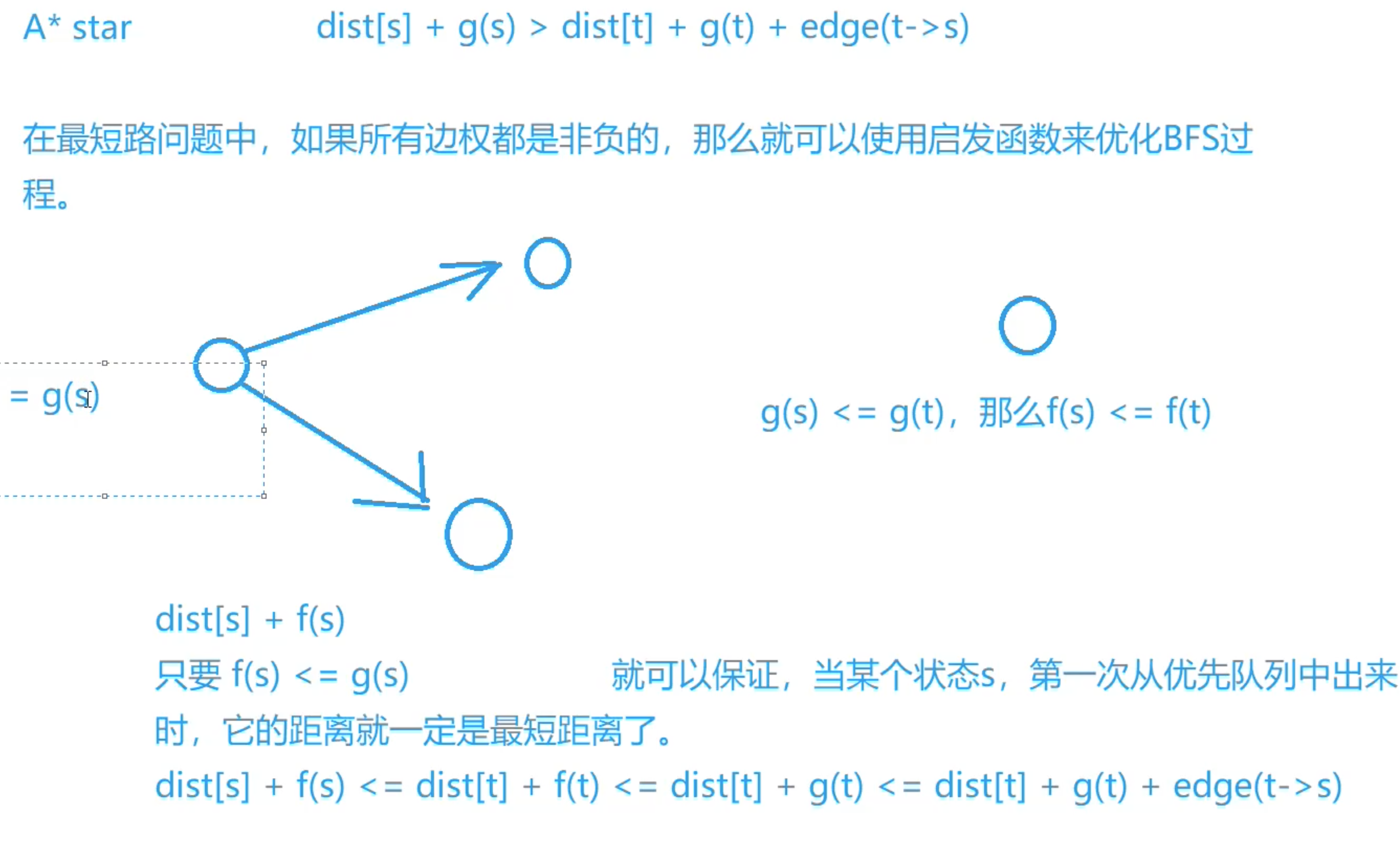
启发函数h(n)的选取
1.曼哈顿距离(城市街区距离)
1 | D*(Math.abs(startX-endsX)+Math.abs(startY-endsY)); |
D为每走一步需要消耗的代价。
如果是只能四个方向走的时候,此时应该是较好的一种方案。
2.欧几里得距离
1 | var a=Math.abs(startX-endsX); |
3.平方后的欧几里得距离
1 | var a=Math.abs(startX-endsX); |
4.对角线距离
1 | D*Math.max(Math.abs(startX-endsX),Math.abs(startY-endsY)); |
帧同步与状态同步
一、同步
所谓同步,就是要多个客户端表现效果是一致的,例如我们玩王者荣耀的时候,需要十个玩家的屏幕显示的英雄位置完全相同、技能释放角度、释放时间完全相同,这个就是同步。就好像很多个人一起跳街舞齐舞,每个人的动作都要保持一致。而对于大多数游戏,不仅客户端的表现要一致,而且需要客户端和服务端的数据是一致的。所以,同步是一个网络游戏概念,只有网络游戏才需要同步,而单机游戏是不需要同步的。
二、状态同步和帧同步的区别
最大的区别就是战斗核心逻辑写在哪,状态同步的战斗逻辑在服务端,帧同步的战斗逻辑在客户端。战斗逻辑是包括技能逻辑、普攻、属性、伤害、移动、AI、检测、碰撞等等的一系列内容,这常常也被视为游戏开发过程中最难的部分。由于核心逻辑必须知道一个场景中的所有实体情况,所以MMO游戏(例如魔兽世界)就必须把战斗逻辑写在服务端,所以MMO游戏必须是状态同步的,因为MMO游戏的客户端承载有限,并不能把整张地图的实体全部展现出来(例如100米以外的NPC和玩家就不显示了),所以客户端没有足够的信息计算全图的人的所有行为。
具体到客户端和服务端通信上,在状态同步下,客户端更像是一个服务端数据的表现层,举个例子,一个英雄的几乎所有属性(例如血量、攻击、防御、攻速、魔法值等等)都是服务端传给客户端的,而且在属性发生改变的时候,服务端需要实时告诉客户端哪些属性改变了,客户端并不能改变这些属性,而是服务端传来多少属性就显示多少属性(虽然可以改变客户端数值达到表现上的效果,例如无限血量,但是服务端那边的血量属性为0时,一样要死)。再举个例子,一个英雄要释放一个非指向性技能(例如伊泽瑞尔的Q),具体的过程就是,客户端通知服务端“我要释放一个技能”-》服务端通知客户端“在某地以什么方向释放某技能”-》客户端根据这些信息创建一个特效放在某地,然后以某个方向飞行-》服务端根据碰撞检测逻辑判断到某个时刻,这个技能碰到了敌方英雄,通知客户端-》客户端根据服务端信息,删除特效,被打的英雄减血同时播放受击特效。
而在帧同步下,通信就比较简单了,服务端只转发操作,不做任何逻辑处理。以下图为例:
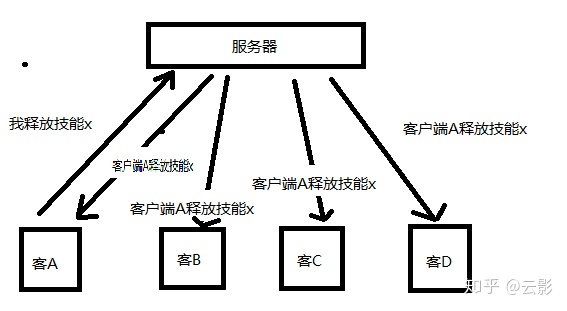
现在同一局里有4个玩家,也就是4个客户端,这时客户端A释放了一个技能x,此时将操作传递给服务端,服务端不做任何判断,直接把A的操作全部分发给ABCD,则ABCD同时让客户端A控制的英雄释放技能x。
三、流量
状态同步比帧同步流量消耗大,例如一个复杂游戏的英雄属性可能有100多条,每次改变都要同步一次属性,这个消耗是巨大的,而帧同步不需要同步属性;例如释放一个技能,服务端需要通知客户端很多条消息(必须是分步的,不然功能做不了),而帧同步就只需要转发一次操作就行了。
四、回放&观战
帧同步的回放&观战比状态同步好做得多,因为只需要保存每局所有人的操作就好了,而状态同步的回放&观战,需要有一个回放&观战服务器,当一局战斗打响,战斗服务器在给客户端发送消息的同时,还需要把这些消息发给放&观战服务器,回放&观战服务器做储存,如果有其他客户端请求回放或者观战,则回放&观战服务器把储存起来的消息按时间发给客户端。
五、安全性
状态同步的安全性比帧同步高很多,因为状态同步的所有逻辑和数值都是在服务端的,如果想作弊,就必须攻击服务器,而攻击服务器的难度比更改自己客户端数据的难度高得多,而且更容易被追踪,被追踪到了还会有极高的法律风险。而帧同步因为所有数据全部在客户端,所以解析客户端的数据之后,就可以轻松达到自己想要的效果,例如moba类游戏的全图挂,吃鸡游戏的透视挂,都是没办法防止的,而更改数据达到胜利的作弊方式(例如更改自己的英雄攻击力)可以通过服务器比对同局其他人的战斗结果来预防。
六、服务器压力
状态同步服务器压力比较大,因为要做更多运算。
七、开发效率
首先要说,状态同步的游戏占主流,其次就是状态同步开发起来比较难。而帧同步服务器开发难度低,同一套方案可以给很多不同类型的游戏使用,反正都是转发操作;减少了服务端客户端沟通,老实说,没有扯皮的时间,开发效率最起码提高20%,状态同步的方案下,同一个功能至少需要一个客户端和服务端共同完成;PVP和PVE基本用的是同一套代码,做完PVP很容易就可以做单机的PVE。
八、使用帧同步的知名游戏
王者荣耀、魔兽争霸3、所有格斗类游戏
九、断线重连
状态同步的断线重连很好做,无非就是把整个场景和人物全部重新生成一遍,各种数值根据服务端提供加到人物身上而已。帧同步的断线重连就比较麻烦了,例如客户端在战场开始的第10秒短线了,第15秒连回来了,就需要服务端把第10秒到第15秒之间5秒内的所有消息一次性发给客户端,然后客户端加速整个游戏的核心逻辑运行速度(例如加速成10倍),直到追上现有进度。
帧同步:
- 客户端按照一定的帧速率(理解为逻辑帧,而不是客户端的渲染帧)去上传当前的操作指令,服务端将操作指令广播给所有客户端,当客户端收到指令后执行本地代码。
状态同步:
- 客户端给服务端直接传递数据和属性,由服务端进行计算。