斯坦福小镇阅读笔记
阉割版:https://www.convex.dev/ai-town
背景
我们如何打造一个反映可信人类行为的交互式人工社会?
从《模拟人生》等沙盒游戏到认知模型和虚拟环境等应用程序,四十多年来,研究人员和从业者一直设想可以作为人类行为可信代理的计算代理。在这些愿景中,计算驱动的代理的行为与他们过去的经验一致,并对他们的环境做出可信的反应。这种对人类行为的模拟可以在虚拟空间和社区中填充现实的社会现象,训练人们如何处理罕见但困难的人际关系情况,测试社会科学理论 ,制作用于理论和可用性测试的人类处理器模型,为无处不在的计算应用程序和社交机器人 提供支持,并支持可以导航复杂人类的不可玩游戏角色开放世界中的关系。
1.在实际实施中,这些方法通常会简化环境或代理行为的维度,以使工作更易管理。基于规则的方法,比如有限状态机(finite-state machines)和行为树(behavior tree),是手工编写代理行为的蛮力方法。它们提供了一种创建简单代理的直接方式,这种方法今天仍然是最主要的方法,甚至可以处理基本的社交互动,如《Mass Effect》和《The Sims》系列游戏中所示。然而,手工制作不可以全面处理开放世界中互动的所有行为。这意味着最终的代理行为可能无法完全代表其互动的后果,也不能执行未在其脚本中硬编码的新程序。
然而,人类行为的空间是广阔而复杂的。
2.尽管大型语言模型在单个时间点上可以模拟人类行为,但确保长期一致性的完全通用智能体将更适合管理不断增长的记忆的体系结构,因为新的交互、冲突和事件会随着时间的推移而产生和消退,同时处理在多个智能体之间展开的级联社会动态。
需要一种方法,能够检索相关事件和长期互动,反思这些记忆以概括和得出更高层次的推论,并应用这种推理来创造计划和反应,在代理人行为的每个时刻乃至更长期的故事情节中产生意义。
实现的效果
场景结构/互动
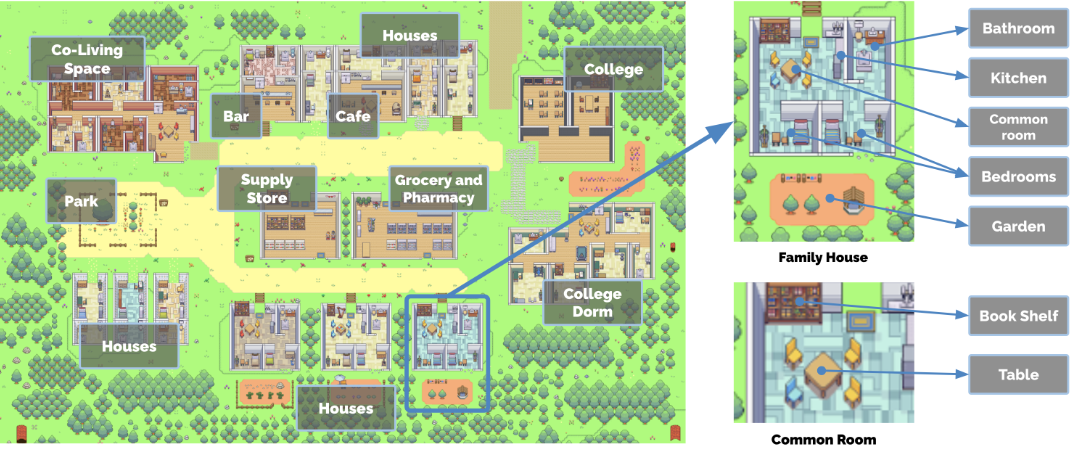
《Smallville》拥有小村庄的常见功能,包括咖啡馆、酒吧、公园、学校、宿舍、房屋和商店。它还定义了使这些空间具有功能性的子区域和对象,例如房屋中的厨房和厨房中的炉灶(见图2)。所有作为代理人主要居住区的空间都设有床、书桌、衣柜、架子、浴室和厨房。代理人在Smallville中的移动方式类似于简单的视频游戏,进入和离开建筑物,导航地图,并接近其他代理人。代理人的移动由生成代理体系结构和沙盒游戏引擎控制:当模型指示代理人将移动到某个位置时,我们在Smallville环境中计算到目的地的步行路径,然后代理人开始移动。此外,用户还可以作为一个代理人进入Smallville的沙盒世界进行操作。用户所扮演的代理人可以是已经存在于世界中的代理人,比如Isabella和John,也可以是一个没有在Smallville中有过历史的外来访客。Smallville的居民将不会与用户控制的代理人有任何不同的对待方式。他们会察觉到其存在,发起互动,并在形成对其看法之前记住其行为。用户和代理人可以影响这个世界中物体的状态,就像在像《模拟人生》这样的沙盒游戏中一样。例如,当代理人正在睡觉时,床可以被占用,当代理人用完食材制作早餐时,冰箱可以是空的。最后,用户还可以通过以自然语言重写代理人周围物体的状态来重新塑造Smallville中的代理人环境。例如,在Isabella早上做早餐时,用户可以通过向系统输入一个命令来选择对象并说明其新状态,像这样:“<Isabella的公寓:厨房:炉灶> 正在燃烧。” Isabella将会在下一刻注意到这一点并去关闭炉灶并重新制作早餐。同样,如果用户将Isabella的淋浴状态设置为“漏水”当她进入浴室时,她将会从她的客厅拿取工具并尝试修理漏水。
生成体的一天
从单一段描述开始,生成代理开始规划他们的一天。随着时间在沙盒世界中流逝,这些代理之间的行为会随着互动和世界的变化而演变,建立记忆和关系,并协调共同的活动。我们通过追踪我们系统的输出来演示生成代理的行为,以代理人John Lin的一天为例(见图3)。在Lin家,John是第一个早上7点醒来的人。他刷牙、淋浴、穿衣、吃早餐,并在客厅的餐桌上查看新闻。早上8点,Eddy紧随其后,匆匆忙忙地离开床准备上课。他在John即将出门时追上了他:
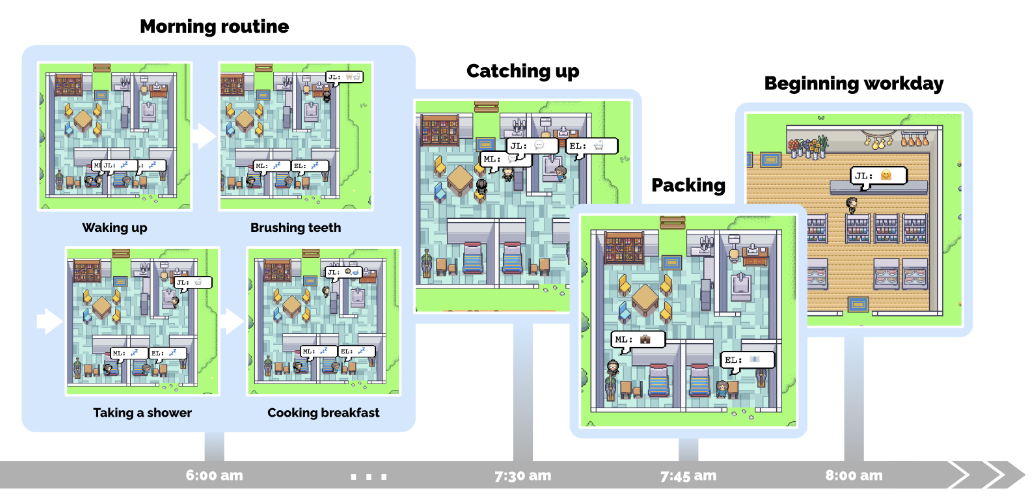
1 | John: 早上好,Eddy。你睡得好吗? |
Eddy出门后不久,Mei醒来并加入了John。Mei询问她的儿子,John回忆起他们刚刚的对话:
1 | Mei: Eddy已经去上学了吗? |
当他们结束对话时,Mei和John开始准备。Mei去教书并继续研究论文,而John在早上9点前在Willow Market and Pharmacy打开他的药房柜台。
自发的社交活动
通过互动,Smallville中的生成代理相互交换信息,建立新关系,并协调共同活动。这些社交行为是 emergent(自发的),而不是预先编程的。
信息传播
1 | Sam: 嗨,Tom,最近怎么样? |
当Sam离开后,Tom和John从另一个消息来源听到这个消息,然后讨论了Sam在选举中获胜的机会:
1 | John: 我听说Sam Moore要竞选地方选举市长。你觉得他有很好的机会吗? |
渐渐地,Sam的竞选成为城里的话题,一些人支持他,而其他人则保持观望。
人脉关系记忆
smallville中的代理随着时间的推移建立新的关系,并记住他们与其他代理的互动。例如,在一开始,Sam不认识Latoya Williams。在Johnson Park散步时,Sam遇到了Latoya,并互相介绍。Latoya提到她正在进行一个摄影项目:“我来这里拍照,为我正在做的项目。”
在以后的互动中,Sam与Latoya的互动表明他记得那次互动,因为他问道:“嗨,Latoya,你的项目进行得怎么样?”而她回答:“嗨,Sam,进展顺利!”
协调与组织
生成代理之间可以相互协调。Isabella Rodriguez在Hobbs Cafe开始计划在2月14日下午5点到7点举行的情人节派对。从这个出发点,代理人在看到朋友和顾客时会邀请他们来Hobbs Cafe或其他地方。随后,Isabella在13日下午装饰了咖啡馆,Maria,是Isabella的常客和亲密朋友,来到了咖啡馆。Isabella请求Maria帮助她装饰派对,Maria答应了。Maria的角色描述提到她喜欢Klaus。那天晚上,Maria邀请了她的暗恋对象Klaus参加派对,他欣然接受。情人节那天,包括Klaus和Maria在内的五名代理人在下午5点来到了Hobbs Cafe,他们享受了派对的欢乐。
在这种情况下,最终用户只设置了Isabella举办派对的初始意图以及Maria对Klaus的暗恋,而传播信息、装饰、邀请对方、参加派对以及在派对上互动等社交行为是由代理体系结构发起的。
overview
我们介绍了生成式智能代理——这些代理借助生成模型来模拟可信的人类行为,并证明它们能够产生可信的个体和紧急组群体行为的模拟。
我们描述了一种架构,通过扩展大型语言模型,以自然语言存储代理的完整经验记录,随着时间将这些记忆合成为更高级别的反思,并动态检索它们以规划行为。
这个架构包含三个主要组成部分。
- 第一个是记忆流,这是一个长期记忆模块,以自然语言记录代理的全面经历列表。一个记忆检索模型结合了相关性、最新性和重要性,以提取需要用于指导代理每时每刻行为的记录。
- 第二个是反思,它将记忆综合成随时间变化的高级推理,使代理能够对自己和其他人做出结论,以更好地指导其行为。
- 第三个是规划,它将这些结论和当前环境翻译成高级行动计划,然后递归地翻译成详细的行为以进行行动和反应。这些反思和计划被反馈到记忆流中,以影响代理未来的行为。
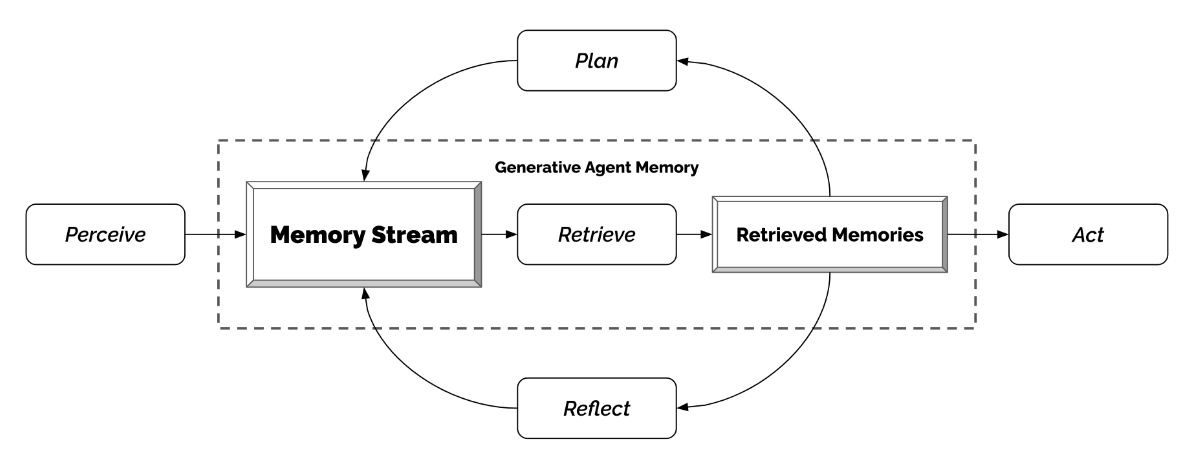
记忆流 Memory and Retrieval
记忆流(memory stream)最基本的元素是 observation :如何实现observation的?
observation(观察)是生成性代理(generative agents)感知到的事件,直接由代理自身的行为或代理感知到的其他代理或非代理对象的行为产生的。例如,如果一个代理在咖啡店工作,它可能会积累以下观察:
- 代理自己正在摆放糕点(Isabella Rodriguez is setting out the pastries).
- 另一个代理正在喝咖啡时学习化学(Maria Lopez is studying for a Chemistry test while drinking coffee).
- 代理和另一个代理正在讨论在咖啡店举办情人节派对的计划(Isabella Rodriguez and Maria Lopez are conversing about planning a Valentine’s day party at Hobbs Cafe).
- 冰箱是空的(The refrigerator is empty).
时近性(Recency)为最近访问的记忆对象分配一个更高的分,使得刚才或今早发生的事情很可能留在智能体的注意力范围内。在我们的实验中,时近性被设计成一个自上次检索记忆以来根据沙盒游戏内小时数呈指数衰减的函数,衰减因子为 0.99。
重要性(Importance)通过为智能体觉得重要的记忆对象赋予更高的得分,将关键记忆和普通记忆区分来开。比如,像在房间内吃早饭这样一件平凡的事情可能会得到一个较低的重要性得分,但是和另一半分手这件事则会有一个较高的得分。重要性评分也会有多种可能的实现方式;我们发现直接让 LLM 来输出一个整数是有效的。完整的 prompt 如下所示:
1 | 在 1 到 10 的范围内,其中 1 是完全普通的(例如刷牙和整理床铺),10 是非常深刻的(例如分手和大学录取),请评估以下记忆片段可能的深刻程度: |
这个 prompt 对于「打扫房间」会返回整数 2,而对「与你的暗恋对象约会」则返回 8。重要性得分会在记忆对象创建的时候生成。
相关性(Relevance)为与当前情况紧密相关的记忆对象分配一个更高的得分。举个例子,如果 query 是一个学生正在和同学讨论化学考试的内容,那么关于他们早餐的记忆对象应该和这件事有较低的相关性,而关于老师和功课的记忆对象应该具有较高的相关性。在实现中,我们使用语言模型为每个记忆的文本描述生成一个 embedding,然后计算记忆 embedding 和 query embedding 的余弦距离作为相关性。
为了计算最终的检索得分,我们用 min-max scaling 将时近性、重要性和相关性都归一化到 [0, 1] 之间。检索时会将上述三个元素进行加权求和作为每条记忆的最终得分:
𝑠𝑐𝑜𝑟𝑒 = $𝛼_{𝑟𝑒𝑐𝑒𝑛𝑐𝑦}$ · 𝑟𝑒𝑐𝑒𝑛𝑐𝑦 + $𝛼_{𝑖𝑚𝑝𝑜𝑟𝑡𝑎𝑛𝑐𝑒}$ · 𝑖𝑚𝑝𝑜𝑟𝑡𝑎𝑛𝑐𝑒 + $𝛼_{𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑐𝑒}$ · 𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑐𝑒
反思 Reflection
挑战:生成式智能体在仅使用原始 observation 时,很难作出概括或者进行推理。考虑这样一个场景,用户问 Klaus Mueller:「如果你必须在你认识的人里面挑一个一起度过一个小时,你怎么选?」。如果只能访问这些原始 observation,那么 Klaus 会直接选择和他互动最频繁的那个人:Wolfgang(他的大学室友)。不幸的是,Wolfgang和Klaus只是经常在对方路过的时候会看到对方,但其实没有过深的交情。更理想的响应要求智能体对「Klaus花费大量精力在研究项目上」的记忆进行概括,以得到「 Klaus对研究充满热忱」这个更高层次的反思,并且同样认识到「Maria在她自己的研究中(虽然是不同的领域)也付出了努力」,这反应出它们可能有共同的兴趣。在第二种方法下,当 Klaus被问到希望和谁度过时光时,Klaus 会选择 Maria 而非Wolfgang。
方案:
反思(reflection)是周期性生成的;在我们的实验中,当智能体感知到的最新事件的重要性分数总和超过某个阈值时,就会形成反思。实际上,智能体每天会反思大约两到三次。
反思的第一步是根据智能体最近的经历确定可以提出的问题,从而确定要反思的内容。我们使用智能体记忆流中的最近 100 条记录(如「Klaus Mueller 正在阅读一本关于中产阶级的书」、「Klaus Mueller 正在与图书馆里员讨论他的研究项目」、「图书馆的办公桌被占用中」等)构造 prompt 来询问 LLM:
1 | 仅考虑上述信息,我们可以回答关于观察对象的陈述中的3个最突出的高层次问题是什么? |
模型的响应生成了候选问题:例如「Klaus Mueller 热衷于什么话题?」、「Klaus Mueller 和 Maria Lopez 的关系是什么?」。我们使用这些生成的问题作为 query 以进行检索,然后为每个问题收集相关的记忆(也包括其它反思)。接着我们通过 prompt 让语言模型进行感悟(insights)并引用特定的记录,这些记录视作感悟产生的依据。完整的 prompt 如下:
1 | 关于 Klaus Mueller 的陈述 |
这个过程会生成像「Klaus Mueller 全身心投入在他对中产阶级的研究上(因为 1, 2, 8, 15)」这样的陈述。我们对它进行解析并以反思的形式存储在记忆流中,包括指向被引用的记忆对象的指针。
智能体不仅在 observations 上进行反思,还会基于其它反思结果进行进一步的反思:比如,上面关于 Klaus Mueller 的第二个陈述是他之前的反思,而不是他在环境中直接观察到的 observation。最终,智能体生成了反思树:叶子结点代表基本的 observations,而非叶子结点代表了思维。随着非叶子结点的高度变高,它所代表的思维也越抽象越高级。
规划
虽然 LLM 可以根据情境信息生成看上去合理的行为,但是智能体需要在更长的一段时间轴上进行规划以确保它们的行为序列的一致性和可信程度。
如果我们将 Klaus 的背景作为 prompt,描述时间,然后询问语言模型他在给定的时刻应该干什么,那么可能的后果是 Klaus 在中午 12 点的时候吃了一次午饭,但是12.30 的时候再吃一次。优化此刻的可信性牺牲了长时的可信性。
规划描述了智能体未来的行为序列并且帮助保持其行为在时间维度上的一致性。一个规划包含地点,开始时间和持续时间。比如,「全神贯注于研究」的 Klaus Mueller 在「迫在眉睫的最后期限」下,可能选择整天都在办公桌前奋笔编写论文。规划的其中一条内容可以更好地说明,比如,「从 2023 年 2 月12 日上午 9 点开始,在Oak Hill 大学的宿舍:Klaus Mueller 的房间:桌子,为研究论文阅读并记笔记」。类似反思,规划也存储在记忆流中,并且可被检索。这使得智能体在决策如何行动时,可以综合考虑观察、反思和规划。智能体在必要的时候会中途改变它们的规划。
规划一个画家智能体在药房柜台一动不动地坐 4 个小时是不现实的,也非常无聊。一个更理想的规划是让它在家工作的4个小时内花一些必要的时间去收集物料、调颜料、休息以及清洁打扫。为了创建这样的规划,我们的方法自上而下递归地生成更多细节。第一步是粗略地制定一个概述当天行程的计划。为了创建初始计划,我们将智能体的摘要性描述(如姓名、特点和最近经历的概括)以及==前一天的摘要作为语言模型的 prompt==。一个完整的 prompt 示例如下,最下面的续写部分交给 LM 完成:
1 | 姓名: Eddy Lin (age: 19) |
这生成了智能体一天规划的大致构想,可以分为 5 到 8 条:
1 | (1)在早上 8 点起床并完成晨间例事 |
智能体会将这个规划保存在记忆流中,然后递归地对它进行拆解以生成更精细的行为。首先按小时级进行拆解:「从下午 1 点到 5 点创作他的新音乐作品」的计划变成:
1 | 下午 1:00: 从对音乐创作进行头脑风暴开始 |
我们接着再对上述计划拆解成 5 - 15 分钟的级别,比如:
1 | 下午 4:00: 吃点零食,比如水果、燕麦棒或者坚果 |
这个过程是可以调整的,以匹配理想的粒度。
4.3.1. Reacting and Updating Plans.
生成式智能体不断执行着动作。在每个时间步,他们感知周围的世界,并将观察到的结果记录在记忆流中。我们将这些 observations 作为 prompt,让语言模型决定智能体应该继续遵循既定的计划,还是作出反应。比如,站在画架前进行绘画可能引发关于画架的 observation,但这不意味着需要作出特别的反应。但是,如果 Eddy 的父亲 John 看到 Eddy 在自家花园散步,那么情况就不一样了。下面是 prompt 的内容,[Agent‘s Summary Description] 代表动态生成的、长长的一段关于智能体目的和处置的摘要,这在 Appendix A 中进行了描述:
1 | [Agent’s Summary Description] |
记忆中相关上下文的摘要是通过如下方法得到的:根据两个模版「[观察者] 和 [被观察实体] 的关系是什么」和「[被观察实体] 正在 [被观察实体的动作状态]」构造prompts,在记忆中进行检索,然后总结在一起。针对上面的例子,语言模型的输出为「John 会考虑向 Eddy 询问关于他的音乐创作项目的事情」。接着我们从这个反应发生的时间开始,重新生成智能体现在的规划。最终,如果动作预示着智能体之间的交互行为,我们会生成他们的对话。
4.3.2. Dialogue.
智能体在交互时会进行对话。我们根据他们对彼此的记忆来调节他们说的话,以实现智能体间的对话。例如,当 John 开始与 Eddy 对话时,我们通过使用他对 Eddy 的记忆摘要以及当他决定向 Eddy 询问他的作曲项目时的预期反应来生成 John 的第一句话:
1 | [Agent’s Summary Description] |
返回的结果是:
1 | 嗨,Eddy。你们班的音乐创作项目进展如何了? |
在艾迪看来,约翰发起对话被看作是他可能想要做出反应的事件。因此,正如约翰所做的那样,埃迪找回并总结了他关于与约翰关系的记忆,以及他的记忆可能与约翰在对话中的最后一句话有关。如果他决定回应,我们就用他总结的记忆和当前的对话历史生成艾迪的话语:
1 | [Agent’s Summary Description] |
这就产生了艾迪的回应:
1 | "嘿,爸爸,一切都好。我一直在花园周围散步,以清除我的头脑,获得一些灵感。" |
不停的根据之前的模板向LLM提prompt,并加入对话历史,==直到其中一方结束对话为止。==
沙盒结构
我们将沙箱环境-区域和对象-表示为树形数据结构,树中的一条边表示沙箱世界中的包含关系。我们将这棵树转换成自然语言传递给生成代理。例如,’灶’作为’厨房’的孩子被渲染成’厨房里有灶’。
当智能体在沙盒世界中航行时,他们更新这棵树以反映新感知的区域。Agent并不是无所不知的:当他们离开某个区域时,他们的树可能会过期,当他们重新进入该区域时,他们的树会更新。
Sandbox Environment Implementation
服务器维护一个 JSON 数据结构,其中包含了沙盒世界中每个智能体的信息(它们当前的位置、当前行为的描述以及正在与哪个对象交互)。在每个沙盒时间步,服务器会解析 JSON 来获取生成式智能体的任何变化、将它们移动到新的位置和更新正在与智能体进行交互的对象的状态
终端用户通过一段简短的自然语言描述初始化一个新的智能体
问题
1)每当一天结束时都会自动生成这一天的摘要提交给第二天作为初始计划吗?这里的摘要是手工生成的吗?
我们的许多 prompts 都需要一个关于智能体的简要描述,在上文中出现的地方都用 [Agent’s Summary Description] 简写了。在实验中,该摘要包括智能体的身份信息(例如姓名、年龄、个性),以及关于它们的主要动机、当前职业和自我评估的描述。由于这个信息在多个 prompts 中频繁使用,我们会定期生成它并将其作为缓存访问。
为了实现这一点,我们用「[姓名] 的主要个性」来进行查询。然后通过 prompt 让语言模型来总结检索结果中的描述信息,比如:
1 | 给定以下陈述,人们会怎么评价 Eddy 的主要个性? |
返回的结果是:
1 | Eddy Lin 是 Oak Hill 学院的一名学生,主修音乐理论和作曲。 他喜欢探索不同的音乐风格,并一直在寻找方法来扩展自己的知识。 |
我们同时对「[姓名] 当前的日常工作」和「[姓名] 对他最近生活进展的感受」采取相同的处理过程。生成的这三个摘要会和智能体的姓名、年龄以及个性拼起来作为缓存的摘要。
2)有没有可能对话一直不结束