SAGA 面向代理的技能到行动生成框架
英文原文 (Original Text)
Announcing SAGA: Skill to Action Generation for Agents.
Demo Video of SAGA in Action
Introduction
Today, we are announcing SAGA: Skill to Action Generation for Agents, a generative AI framework that steers AI Agents toward successful goals through Actions. SAGA is inspired in part by Joon Park’s Generative Agents paper where Agents inhabit the 2D simulated town of Smallville. As well as the work on Voyager from Jim Fan, et al, in which Agents have a set of predefined Skills they can choose from but can also create new skills as they perform tasks in the 3D game, MineCraft.
You can find the code on GitHub.
A Day in Thistle Gulch - Blackjack and Sheriff Cooper work to thwart each other’s plans
中文翻译 (Chinese Translation)
宣布SAGA:面向代理的技能到行动生成框架
SAGA实际运行的演示视频
简介
今天,我们宣布推出SAGA:面向代理的技能到行动生成框架(Skill to Action Generation for Agents),这是一个通过行动引导AI代理实现成功目标的生成式AI框架。SAGA的部分灵感来自Joon Park的生成式代理(Generative Agents)论文,该论文中的代理居住在名为Smallville的2D模拟小镇中。同时也受到Jim Fan等人开发的Voyager项目的启发,在该项目中,代理拥有一组预定义的技能可供选择,但也可以在执行3D游戏Minecraft中的任务时创建新技能。
您可以在GitHub上找到代码。
蓟草峡谷的一天 - Blackjack和Sheriff Cooper努力阻挠彼此的计划
英文原文 (Original Text)
Skills in Action
With SAGA, Agents first tell SAGA contextual metadata about themselves and their world via a companion simulation: Who they are; What they know; What “Skills” they have; And what their goals are. Then, when an Agent is deciding what to do next, SAGA generates a set of “Actions” that best serve the Agent’s goals in that moment. These Action options are then scored and returned to the simulation in order to direct the Agent. This process repeats each time the Agent is deciding its next action and can be scaled to multiple agents running simultaneously.
An Action is just an implementation of a Skill as we will discuss. For now, think of Skills as a list of tools in a toolbox that the AI can employ in a specific way to advance a goal. For instance “Talk To” is a Skill, where an Agent can go talk to someone. If the Agent’s goal is to investigate a crime, then “Talk To
Examples
Examples of how Skills become Actions
中文翻译 (Chinese Translation)
技能付诸行动
通过SAGA,代理首先通过配套模拟向SAGA提供关于自身和所处世界的上下文元数据:他们是谁;他们知道什么;他们拥有哪些”技能”;以及他们的目标是什么。然后,当代理决定下一步行动时,SAGA会生成一系列最能满足代理当前目标的”行动”。这些行动选项随后会被评分并返回给模拟系统,以指导代理。每当代理决定其下一步行动时,这个过程就会重复一次,并且可以扩展到多个同时运行的代理。
正如我们将讨论的,行动只是技能的一种实现。现在,可以将技能视为AI可以以特定方式使用的工具箱中的工具列表,以推进目标。例如,”与某人交谈”是一种技能,代理可以去与某人交谈。如果代理的目标是调查犯罪,那么”与<某人>谈论<某话题>”就形成了一个特定的行动,代理随后可以执行这个行动。
示例
技能如何转变为行动的示例

英文原文 (Original Text)
Pairing With a Simulation
SAGA is B.Y.O.S.: Bring Your Own Simulation
SAGA is a B.Y.O.S. or Bring Your Own Simulation framework.
After responding with Action options, SAGA’s work is mostly done. It still receives information from the paired simulation it is connected to, but simulating the action itself, including generating conversations, or moving around an environment is left to the simulation to implement.
A set of starter Skills that leverage parts of our proprietary simulation (not currently publicly available) is provided, but other simulations, even very simple ones with only a few Skills, can be used as an alternative via the python library or by connecting to the framework over a network via its built-in socket-io server. See the Github repository for more information on documentation and integrating with your own simulation.
Using a preview of our Thistle Gulch simulation, let’s explore a more contextual example of how SAGA works in practice. Note that Thistle Gulch is still in development, so the details and visuals here are all subject to change. We will be announcing more about Thistle Gulch and “The Simulation” framework it’s built upon in the future.
中文翻译 (Chinese Translation)
与模拟系统配对
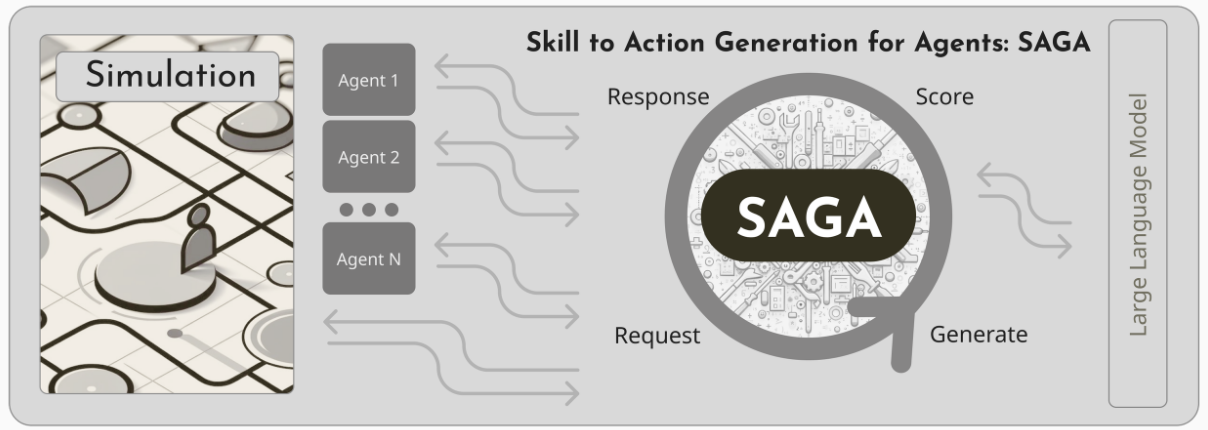
SAGA是B.Y.O.S.:自带模拟系统(Bring Your Own Simulation)
SAGA是一个B.Y.O.S.或自带模拟系统框架。
在响应行动选项后,SAGA的工作基本完成。它仍然接收来自所连接的配对模拟系统的信息,但模拟行动本身,包括生成对话或在环境中移动,都留给模拟系统来实现。
我们提供了一套利用我们专有模拟系统(目前尚未公开)部分功能的入门技能,但其他模拟系统,即使是只有少量技能的非常简单的系统,也可以通过Python库或通过网络连接到框架的内置socket-io服务器作为替代方案。有关文档和与您自己的模拟系统集成的更多信息,请参阅GitHub存储库。
使用我们的蓟草峡谷模拟预览版,让我们探索一个更具上下文的SAGA实际工作方式示例。请注意,蓟草峡谷仍在开发中,因此这里的细节和视觉效果都可能发生变化。我们将在未来宣布更多关于蓟草峡谷和它所基于的”The Simulation”框架的信息。
英文原文 (Original Text)
Murder in Thistle Gulch
Thistle Gulch is a simulation of a fictional 1800’s Wild-West Town by the same name. It’s currently inhabited by 17 or so characters, but we’ll mainly first focus on two of them.
Personas
Let’s briefly explore Blackjack and Sheriff Cooper’s Personas. This is just a brief summary of their data. They also have detailed backstories and memories.
Blackjack vs Sheriff Cooper
Meta-Memories
In order to generate Actions, the simulation needs to provide SAGA with relevant details we call “Meta-Memories”. These are the sum of all the relevant metadata surrounding the simulated world and its Agents. Some of this information will only be available to specific characters, like memories and observations. Other information is shared across characters like the locations, interactable objects, and summaries of other characters.
Meta-Memories are loaded just before the simulation starts or are streamed in while the simulation is running, as events unfold. This includes details about the activities other characters are performing, their conversations, and new memories that are formed as the simulation progresses.
中文翻译 (Chinese Translation)
蓟草峡谷中的谋杀案
蓟草峡谷是一个虚构的19世纪美国西部同名小镇的模拟。目前居住着约17个角色,但我们主要首先关注其中的两个。
角色设定
让我们简要探讨Blackjack和Sheriff Cooper的角色设定。这只是他们数据的简要总结。他们还有详细的背景故事和记忆。
Blackjack与Sheriff Cooper的对比

元记忆
为了生成行动,模拟系统需要向SAGA提供我们称为”元记忆”的相关细节。这些是围绕模拟世界及其代理的所有相关元数据的总和。某些信息只对特定角色可用,如记忆和观察结果。其他信息则在角色之间共享,如位置、可交互对象和其他角色的概述。
元记忆在模拟开始前加载,或者在模拟运行时随着事件的展开而流入。这包括其他角色正在执行的活动、他们的对话以及随着模拟进展而形成的新记忆等详细信息。
英文原文 (Original Text)
The Murder Investigation
The Sheriff considers what the evidence means
To test SAGA, we created an example scenario within Thistle Gulch where characters are forced to make choices about what to do next with clear and time sensitive goals, and constraints that confound those goals: The murder of a local native.
In our fictional scenario, a native from the local tribe was found dead just outside of town. The tribe’s chief has threatened to take things into his own hands if Sheriff Cooper doesn’t uncover the murderer quickly. Blackjack, the saloon owner and local gang leader, is also unsure who the murderer is, but he doesn’t want any investigation to blow back on him and ruin his plans to rob the stagecoach in a few weeks.
As the sun rises over Thistle Gulch on the start of Day 1, the Sheriff is standing next to the native’s remains and Blackjack is standing in his Saloon. Both are Agents and separately deciding what to do next via SAGA. The Meta-Memory of this 3 day window in which to solve the case encourages the characters to move forward in their own ways and achieve a timely conclusion.
Sheriff Cooper
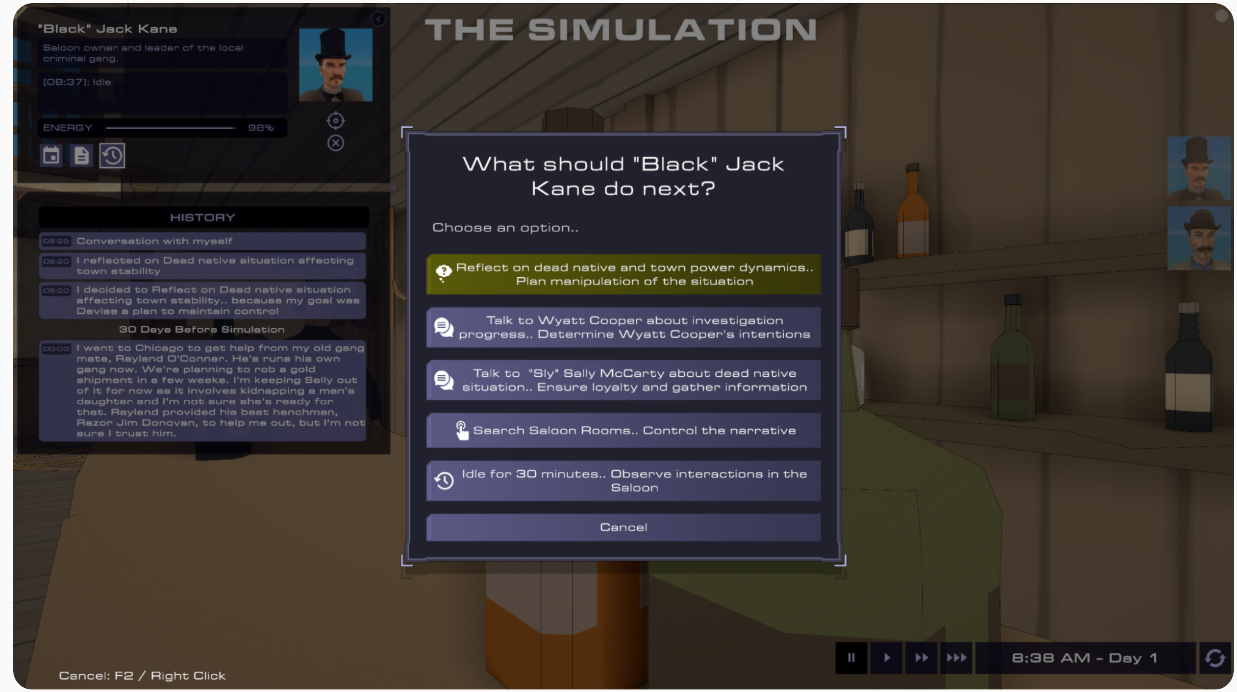
Sheriff Wyatt Cooper, choosing from the list of Actions provided by SAGA, first decides to do the “Search Near the Dead Native” Action, which uses his “interact” Skill. The “interact” Skill has access to a list of all interactable simulation objects and what interactions, often human authored, they afford the agent. Here, the generated Action becomes “Interact with
After discovering blood and bullet casings during that interaction, SAGA uses yet another skill called “reflect”. The Action becomes “Reflect on
Saloon Owner
For Blackjack’s Agent, SAGA leverages the “Reflect” Skill to generate the “Reflect on
中文翻译 (Chinese Translation)
谋杀调查

警长思考证据的含义
为了测试SAGA,我们在蓟草峡谷中创建了一个示例场景,角色被迫在明确且时间敏感的目标下做出关于下一步行动的选择,同时面临阻碍这些目标的约束条件:一名当地原住民被谋杀的案件。
在我们的虚构场景中,一名来自当地部落的原住民在镇外被发现死亡。部落酋长威胁说,如果Sheriff Cooper不能迅速找出凶手,他将亲自处理此事。酒馆老板兼当地帮派头目Blackjack也不确定谁是凶手,但他不希望任何调查影响到他几周后抢劫马车的计划。
在第一天开始时,当太阳升起在蓟草峡谷上空,警长站在原住民遗体旁,而Blackjack则站在他的酒馆里。两人都是代理,通过SAGA分别决定下一步行动。关于这个3天时间窗口内解决案件的元记忆鼓励角色们以自己的方式前进并及时得出结论。
Sheriff Cooper
Sheriff Wyatt Cooper从SAGA提供的行动列表中选择,首先决定执行”搜索死去的原住民附近”的行动,这使用了他的”交互”技能。”交互”技能可以访问所有可交互的模拟对象列表以及它们提供给代理的交互方式,这些交互方式通常是由人类编写的。在这里,生成的行动变成了”与<死去的原住民>交互并执行它提供的<搜索死去的原住民附近>交互”。
在那次交互中发现血迹和弹壳后,SAGA使用了另一个名为”反思”的技能。行动变成了”反思<血迹新鲜且有弹壳>”,他决定立即深入调查这个案件,正如在蓟草峡谷UI中与自己的对话所示。

酒馆老板
对于Blackjack的代理,SAGA利用”反思”技能生成了”反思<死去原住民情况影响镇上稳定>”的行动。然后他决定引导调查结果朝着有利于自己和计划的方向发展。

英文原文 (Original Text)
After Blackjack is done Reflecting, he needs to decide what skill to use next and how to use that skill. A request is sent to SAGA which returns the following Actions. Each Action has an associated Skill, as shown by the different icons in the image below. As each Action is generated, a given Skill’s parameters are filled in by SAGA’s generative model.
Action options generated for Blackjack
Cooperation and Conflict
Blackjack and Sheriff Cooper are now in conflict with each other. The Sheriff wants to solve the crime, and Blackjack wants to make sure the investigation doesn’t ruin his plans. They continue to navigate this situation and pursue their disparate goals by generating and then choosing Actions via SAGA as the simulation progresses.
As both Agents are pursuing their own ends, they are also cooperating with other Agents. The Sheriff talks to the townsfolk looking for leads and cooperation, while Blackjack conspires with his gang to plant evidence and spread rumors to throw him off.
They may also manipulate the world and not just people to their own ends. The Sheriff will move the native’s body into the jail to preserve the evidence or Blackjack and his goons will find something incriminating and plant that evidence in the scapegoat’s room to frame them for the murder.
The Thistle Gulch demo video above shows Blackjack cooperating with his gang to draw the sheriff’s attention away from his criminal schemes. While the dialogue is generated by our Simulation, who to talk to and what the topic and goal of the conversations are all generated via SAGA.
The sheriff and Blackjack are both leveraging SAGA to generate candidate Actions, but here the Sheriff is choosing the option with the highest score automatically. Blackjack pauses when SAGA returns the options so we can see them all. The top option is the highest scoring and is the default choice, but they can also be chosen manually as shown in the video. The video has been edited for time and viewability, but the run wasn’t cherry-picked.
中文翻译 (Chinese Translation)
在Blackjack完成反思后,他需要决定下一步使用什么技能以及如何使用该技能。向SAGA发送请求,SAGA返回以下行动。每个行动都有一个相关联的技能,如下图中不同图标所示。随着每个行动的生成,SAGA的生成模型会填充给定技能的参数。
为Blackjack生成的行动选项
合作与冲突
Blackjack和Sheriff Cooper现在处于相互冲突状态。警长想要解决犯罪,而Blackjack想确保调查不会破坏他的计划。他们继续在这种情况下导航并通过SAGA生成和选择行动来追求各自不同的目标,随着模拟的进行。
当两个代理追求各自的目标时,他们也在与其他代理合作。警长与镇民交谈寻找线索和合作,而Blackjack则与他的帮派密谋栽赃和散布谣言以转移注意力。
他们也可能操纵世界而不仅仅是人。警长会将原住民的尸体移到监狱以保存证据,或者Blackjack和他的手下会找到一些罪证并将其栽赃到替罪羊的房间以嫁祸他们谋杀。
上面的蓟草峡谷演示视频显示Blackjack与他的帮派合作,将警长的注意力从他的犯罪计划上转移开。虽然对话是由我们的模拟系统生成的,但与谁交谈以及对话的主题和目标都是通过SAGA生成的。
警长和Blackjack都在利用SAGA生成候选行动,但在这里,警长自动选择得分最高的选项。Blackjack在SAGA返回选项时暂停,以便我们可以看到所有选项。最高选项是得分最高的,是默认选择,但它们也可以如视频所示手动选择。视频已经为了时间和可观看性而编辑,但运行并非精心挑选。
英文原文 (Original Text)
Sheriff Cooper convinces Sally McCarty to betray Blackjack
While most of the time it goes somewhere useful, it can make connections or assumptions that turn out to be counter productive. For instance, even though the murder of the old Sheriff happened a year ago and the case has now gone cold, Wyatt may try to connect the native’s murder investigation back to that old case in a way that feels like he’s getting distracted. As someone with ADD, I know this can be realistic, but the audience will likely question that abrupt change in focus, and result in a less interesting narrative outcome.
The variation between different iterations of the simulation is based on the SAGA prompt and the LLM settings, but with so much contextual information available, the Agents reliably stay true to their characterization. The Action options that are generated, the scores of those actions, and then of course the simulation itself all have impacts that create the main opportunities for variation.
We often call this phenomenon “hallucination” on the part of the LLM, but Karpathy made a great point recently that, “hallucination is all LLMs do.” So, hallucination is not really the problem we need to solve, but the nature of the tool we’re using and “it’s greatest feature”. It’s up to us to best guide the model and handle the responses it provides us without locking it down so much that we don’t get what we actually want from it.
Andrej Karpathy Tweet on the “Hallucination Problem”
When using a robust simulation like ours, we take the responses that come back from SAGA and do additional validation on them like making sure they are using valid entities in their parameters before even considering them as options. We can also score options and even outcomes through multiple runs of the simulation to generate data for RLHF and fine-tune custom models on the behavior we want it to focus on next time.
中文翻译 (Chinese Translation)
Sheriff Cooper说服Sally McCarty背叛Blackjack

虽然大多数时候它会产生有用的结果,但它也可能做出不利于生产力的连接或假设。例如,即使旧警长的谋杀案发生在一年前,案件现已冷却,Wyatt可能会尝试将原住民谋杀调查与那个旧案件以一种看起来像是分心的方式联系起来。作为一个有注意力缺陷障碍的人,我知道这可能是现实的,但观众可能会质疑那种突然的焦点转变,并导致叙事结果不那么有趣。
模拟不同迭代之间的变化基于SAGA提示和LLM设置,但有了如此多的上下文信息,代理可靠地保持其特征。生成的行动选项、这些行动的分数,当然还有模拟本身都有影响,创造了变化的主要机会。
我们经常称这种现象为LLM的”幻觉”,但Karpathy最近指出,”幻觉是所有LLM都会做的事”。所以,幻觉并不是我们需要解决的问题,而是工具的本质和”它最大的特点”。我们的任务是最好地引导模型并处理它提供的响应,而不是过度限制它以至于我们无法从中获得我们真正想要的东西。
Andrej Karpathy关于”幻觉问题”的推文

当使用像我们这样的强大模拟系统时,我们会对从SAGA返回的响应进行额外验证,比如确保它们在参数中使用有效实体,然后才考虑它们作为选项。我们还可以通过模拟的多次运行对选项甚至结果进行评分,以生成RLHF数据并微调自定义模型,关注我们希望它下次关注的行为。
英文原文 (Original Text)
Related Work
SAGA is leveraging a technique called “tool-use” popularized by the likes of AutoGPT and ChatGPT (Functions). Like these other projects, SAGA is a tool that builds upon the work of many others and shouldn’t be considered a research paper or fancy new model, but it does achieve very interesting results in a usable package for anyone to extend and experiment with.
In fact, the Skills definitions can be expanded to other domains like “Search The Web”, “Generate an Image”, or “Recall from Vector Database” if you like. Here, we are focusing on Actions that better match the simulation of human-like characters in a narrative context.
AI Planning in Context
Reinforcement Learning in which Agents leverage deep learning to play video games goes back a decade and more, but they have to learn how to play. With Large Language Models (LLMs), one simply has to provide contextual information, perhaps some examples, and then instruct the LLM to complete useful information to reach the goal. Of course this works best for domains where the LLM has seen representative training data, but in the case of human actions, this data is very common in the training set of the Web – we humans do like to talk about ourselves.
There is also a large space of work in what is generally called “AI Planning” which goes all the way back to the famous “Shakey the Robot” in the late 60s that could break a command down into individualized steps itself. Notably, “Shakey” research is where we get the A* algorithm and the Hough transform, a precursor to Convolutional Neural Nets. There is a lot of interest in using LLMs for Planning right now, be that in robotics, coding and more.
中文翻译 (Chinese Translation)
相关工作
SAGA利用了一种称为”工具使用”的技术,这种技术由AutoGPT和ChatGPT(Functions)等项目普及。与这些其他项目一样,SAGA是一个建立在许多其他人工作基础上的工具,不应被视为研究论文或花哨的新模型,但它确实在一个可用的包中实现了非常有趣的结果,任何人都可以扩展和实验。
事实上,技能定义可以扩展到其他领域,如”搜索网络”、”生成图像”或”从向量数据库中召回”,如果你愿意的话。在这里,我们专注于更好地匹配在叙事上下文中模拟类人角色的行动。
AI规划的上下文
强化学习中代理利用深度学习玩视频游戏的历史可以追溯到十多年前,但它们必须学习如何玩游戏。使用大型语言模型(LLM),只需提供上下文信息,也许一些例子,然后指示LLM完成有用的信息以达到目标。当然,这对于LLM已经见过代表性训练数据的领域效果最好,但在人类行为的情况下,这些数据在网络的训练集中非常常见 - 我们人类喜欢谈论自己。
还有一大类被广泛称为”AI规划”的工作,可以追溯到60年代末著名的”Shakey机器人”,它可以将命令分解为自己的个性化步骤。值得注意的是,”Shakey”研究是我们获得A*算法和Hough变换的地方,后者是卷积神经网络的前身。现在在机器人、编码等领域使用LLM进行规划有很多兴趣。
英文原文 (Original Text)
Language Models as Zero-Shot Planners
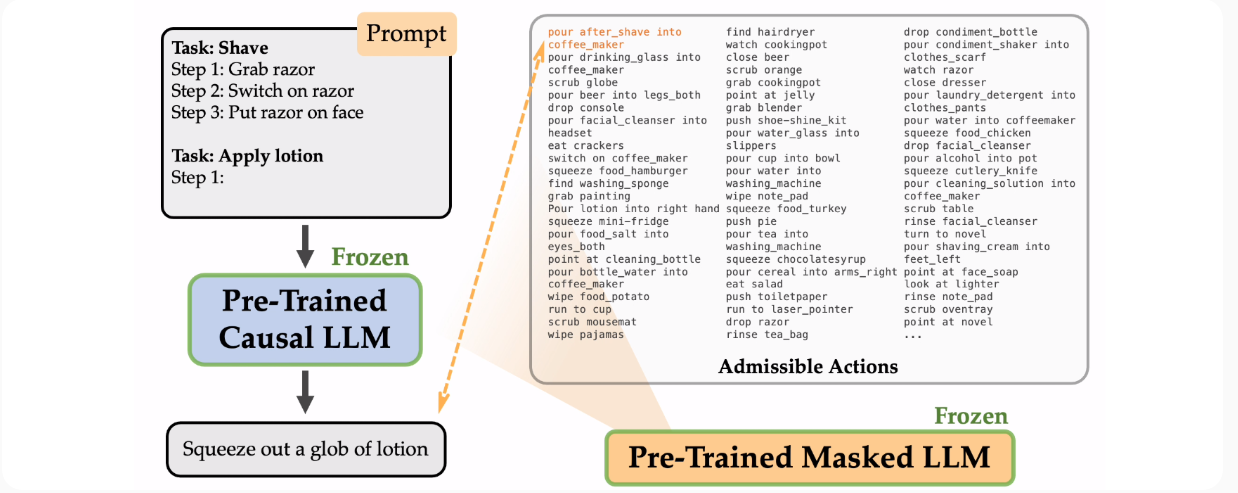
The closest analog for this work is probably the paper, “Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents” from Huang and Abbeel in Jan 2022 that generated action plans for tasks like “Brush teeth”. There, they fine-tuned an LLM on “admissible actions” or actions that could actually be recognized by the VirtualHome simulator instead of just free-form instructions that the simulator wouldn’t recognize.
Diagram from Language Models as Zero-Shot Planners
Currently, SAGA doesn’t generate a whole action plan of small steps, instead it generates a list of candidate next-step-actions that are very high-level and parameterizable. This allows the Model to focus on a smaller set of high-level tools that it can apply in a multitude of ways instead of using lower-level or very specific steps to construct an action plan. This has benefits that fine-tuning isn’t necessary and allows the simulation to take on more of the burden of providing and executing the actions, saving time and money for those using a model like GPT-4.
Generative Human-like Agents
In 2023, a lot of additional work has been done in this space, but we will highlight two for now that were also inspirational for how SAGA is architected, the terminology, and getting SAGA released. How SAGA may take a different approach than these projects is also highlighted.
Diagram from Generative Agents Paper
Generative Agents: Interactive Simulacra of Human Behavior, Park, et al Apr 2023. Here, Joon created a simple simulation in the browser using a 2D-grid game engine backed by a Python webserver. It also has another Python server running the code that drives the agents. The two communicate by saving a series of specially named files containing either the simulation data (locations of the agents in space), or what actions the agents should take in this step. All agents are evaluated each step and there is interesting work that explores observations, daily planning, and vector database storage/retrieval of memories.
Outside of research, that architecture makes it difficult to make use of in practice. The lock-step approach also takes a long time between steps and with the complex LLM re-processing overhead it can be very expensive to run for someone just looking to experiment.
中文翻译 (Chinese Translation)
作为零样本规划器的语言模型
这项工作最接近的类比可能是这篇论文,“Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”,由Huang和Abbeel于2022年1月发表,该论文为”刷牙”等任务生成行动计划。在那里,他们对LLM进行了微调,使其能够识别”可接受的行动”,即VirtualHome模拟器可以实际识别的行动,而不是模拟器无法识别的自由形式指令。
来自《作为零样本规划器的语言模型》的图表
目前,SAGA不生成由小步骤组成的完整行动计划,而是生成一个可参数化的高级候选下一步行动列表。这允许模型专注于一组更小的高级工具,它可以以多种方式应用,而不是使用低级或非常具体的步骤构建行动计划。这有好处,不需要微调,并允许模拟承担更多提供和执行行动的负担,为使用像GPT-4这样的模型的人节省时间和金钱。
生成式类人代理
2023年,在这个领域已经完成了大量额外的工作,但我们现在将重点介绍两个对SAGA的架构、术语和发布有启发作用的项目。SAGA可能采取与这些项目不同的方法,这一点也被强调。
来自生成式代理论文的图表
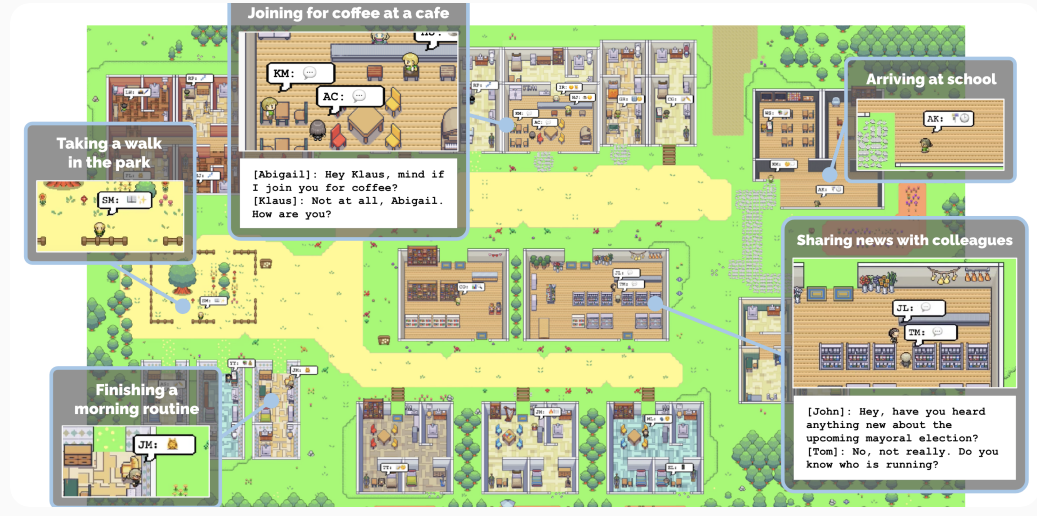
Generative Agents: Interactive Simulacra of Human Behavior,Park等人,2023年4月。在这里,Joon创建了一个在浏览器中使用2D网格游戏引擎的简单模拟,由Python网络服务器支持。它还有另一个运行驱动代理代码的Python服务器。两者通过保存包含模拟数据(代理在空间中的位置)或代理在此步骤中应采取的行动的特殊命名文件进行通信。所有代理在每一步都被评估,有一些有趣的工作探索观察、日常规划和向量数据库存储/检索记忆。
在研究之外,这种架构使其难以实际使用。锁步方法也需要在步骤之间花费很长时间,并且由于复杂的LLM重新处理开销,运行可能非常昂贵,对于只想实验的人来说。
英文原文 (Original Text)
SAGA takes a different approach. It’s available via socket.io so it communicates asynchronously over the web or on a local network. That means Agents and the Simulation don’t need to pause the world while waiting for Actions to be generated, though you can still do that if you like. It also provides a cleaner abstraction between the simulation and what is generating actions. SAGA does the generation based on requests for Actions, and the simulation is free to interpret those actions as it needs.
Interacting With and Planning in a 3D World
Diagram from Voyager Paper
Voyager: An Open-Ended Embodied Agent with LLMs - Jim Fan’s team May 2023. Shortly after “Generative Agents” in 2023 we got “Voyager”, a follow up to Fan’s Team’s “MineDojo” paper and tool of the same name from 2022. Together, they provide an open 3D world by connecting to the popular game MineCraft. MineCraft is the simulation environment and Voyager connects to it via an API that bridges the two called “MineFlayer”. There are no plans to connect SAGA to Minecraft, but pull requests are welcome!
Voyager also goes beyond the current scope of SAGA as it’s a research project focused on “Life-long learning” and creating new skills via code generation and refinement while essentially leveling the Agent up in Minecraft and learning to craft new things along the way.
However, Minecraft is a pretty limited simulator for human-like experiences, especially with multiple agents in dialog with each other. Thistle Gulch is mostly concerned with narrative outcomes, so we prioritize Actions that match the Agent’s personality, history, memory and relationships. Our Agents, Blackjack and the Sheriff, are also characters in a Narrative, so we want them to perform their narrative roles and achieve satisfying narrative outcomes as well.
中文翻译 (Chinese Translation)
SAGA采取了不同的方法。它通过socket.io可用,因此它通过网络或在本地网络上异步通信。这意味着代理和模拟不需要在等待生成行动时暂停世界,尽管如果你愿意,你仍然可以这样做。它还提供了模拟和生成行动之间更清晰的抽象。SAGA基于行动请求进行生成,模拟系统可以根据需要自由解释这些行动。
在3D世界中交互和规划
来自Voyager论文的图表
Voyager: An Open-Ended Embodied Agent with LLMs - Jim Fan的团队,2023年5月。在2023年”Generative Agents”之后不久,我们得到了”Voyager”,这是对Fan的团队2022年的”MineDojo”论文和同名工具的后续。它们共同提供了一个开放的3D世界,通过连接到流行游戏Minecraft。Minecraft是模拟环境,Voyager通过一个名为”MineFlayer”的API桥接连接到它。目前没有计划将SAGA连接到Minecraft,但欢迎提出请求!
Voyager还超出了SAGA的当前范围,因为它是一个专注于”终身学习”和通过代码生成和改进创建新技能的研究项目,同时本质上在Minecraft中提升代理的等级并学习制作新物品。
然而,Minecraft作为人类般体验的模拟器相当有限,特别是在多个代理相互对话的情况下。蓟草峡谷主要关注叙事结果,因此我们优先考虑与代理的个性、历史、记忆和关系相匹配的行动。我们的代理,Blackjack和警长,也是叙事中的角色,所以我们希望他们执行其叙事角色并实现令人满意的叙事结果。
英文原文 (Original Text)
Next Steps
What’s next for SAGA and where do we see it headed? As a v1 release, SAGA is functional but we will continue to support and improve it over time while looking to grow a community interested in it and its applications.
Challenges for Production Use
Generation Times
Right now, Generation on the latest GPT-3.5 takes around 3 seconds for 5 Action options, and GPT-4 takes around 30 seconds. The generation time is directly related to the number of generated tokens, not the input prompt so SAGA users should experiment which model and the number of options they actually need in their own context. Right now, this generation of options happens in one LLM request which optimizes input token costs, but it can be parallelized instead. For our demo video, we paused the world while waiting for options to generate and then cut that for time. SAGA already parallelizes the per-character requests so the number of characters doesn’t directly affect the wall-clock generation time.
Memory and Prompt Size Limits
SAGA keeps the memory model simple at this point, using lists and dictionaries in memory to index and retrieve the records provided by the simulation. Using LLMs with larger prompts and limiting the metadata to recent or important events is a way to expand the amount of Meta-Memories possible without hitting model context window limits. The latest GPT-4 OpenAI models have a 128K token limit now, nearly 100x larger than it was a few years ago.
To increase the number of Meta-Memories, say to increase the number of characters in the world, their relationships, their individual knowledge, and their memories of events, more complex storage and retrieval techniques are needed. Generation of embeddings to store and retrieve Meta-Memories with Vector DBs like FAISS, knowledge graphs, or even SQL databases to preserve memories are useful techniques to explore, but needs will vary and engineering is all about tradeoffs so we leave those to the user for now.
中文翻译 (Chinese Translation)
下一步
SAGA的下一步是什么,我们认为它将走向何方?作为v1版本,SAGA是功能性的,但我们将继续支持并随着时间改进它,同时寻求建立一个对它及其应用感兴趣的社区。
生产使用的挑战
生成时间
目前,在最新的GPT-3.5上生成大约需要3秒钟生成5个行动选项,而GPT-4需要大约30秒。生成时间与生成的令牌数量直接相关,而不是输入提示,因此SAGA用户应该实验哪种模型以及在自己的上下文中实际需要的选项数量。目前,这种选项生成发生在一个LLM请求中,这优化了输入令牌成本,但它也可以并行化。对于我们的演示视频,我们在等待选项生成时暂停了世界,然后为了节省时间而剪辑了视频。SAGA已经并行化了每个角色的请求,因此角色数量不会直接影响挂钟生成时间。
内存和提示大小限制
SAGA目前保持内存模型简单,使用内存中的列表和字典来索引和检索模拟提供的记录。使用具有更大提示和限制元数据到最近或重要事件的LLM是扩展可能的元记忆量而不触及模型上下文窗口限制的一种方法。最新的GPT-4 OpenAI模型现在有128K令牌限制,几乎比几年前大100倍。
要增加元记忆的数量,比如增加世界中的角色数量、它们的关系、它们的个人知识以及它们对事件的记忆,需要更复杂的存储和检索技术。生成嵌入以存储和检索带有向量数据库(如FAISS)、知识图或甚至SQL数据库的元记忆是值得探索的有用技术,但需求会有所不同,工程都是关于权衡的,所以我们暂时将这些留给用户。
英文原文 (Original Text)
SAGA’s Future Goals
As the goal of SAGA is steering AI Agents toward successful goals through Actions, the next logical step is to improve those generated Actions. There’s a number of exciting research areas exploring this space lately.
For instance, SAGA already uses a “test-time compute” tradeoff technique of generating multiple candidate options and then validating and scoring the answers before choosing the best one as a way to get much better results without training a custom model. Related techniques include “Chain-of-thought” and “Tree-of-thought” or search based techniques used in AlphaGo where a model is trained to predict how good an option is likely to be through self-play.
Improving the Skills (the tools the model has to choose from) also increases the quality of the Actions. For instance, we are working on the “exchange” skill that allows characters to buy, sell, steal, and give items in their inventory. Creating new Skills via code generation like Voyager does, or at least chaining together existing skills to form action-plans is an exciting area of research as well.
Since SAGA doesn’t ship with a simulation out of the box in order to get started, we will be looking to add a simple text-based simulation to quickly test it out, but we think it’s important to keep the simulation itself separate from SAGA in order to be sim-agnostic. We will be looking for others who want to build their own simulation or use it with existing open source simulators and expect to see rapid support for simple 2D simulations that appeared after the Generate Agents paper.
Other simulations will have Agents within Gaming or Reinforcement Learning scenarios. Some simulations are engaged in RPG combat like the Neurips MMO Challenge happening this week. We’re excited to build upon SAGA, but also excited to see how the community uses it and contributes back. Check out the GitHub repo for more information.
[AI] · [Simulations] · [Agents] · [Tool-Use]
[Previous Previous Thistle Gulch Simulation Beta Op…]
[Next Next SAGA Now Available: Open Source]
中文翻译 (Chinese Translation)
SAGA的未来目标
由于SAGA的目标是通过行动引导AI代理实现成功目标,下一个合乎逻辑的步骤是改进这些生成的行动。最近有许多令人兴奋的研究领域在探索这个空间。
例如,SAGA已经使用”测试时计算”权衡技术,生成多个候选选项,然后在选择最佳选项之前验证和评分答案,作为一种在不训练自定义模型的情况下获得更好结果的方法。相关技术包括”思维链”和”思维树”或基于搜索的技术,用于AlphaGo,其中模型被训练预测通过自我对弈选项可能有多好。
改进技能(模型可以选择的工具)也会提高行动的质量。例如,我们正在开发”交换”技能,允许角色在其库存中购买、出售、偷窃和赠送物品。像Voyager那样通过代码生成创建新技能,或者至少将现有技能链接在一起形成行动计划,是一个令人兴奋的研究领域。
由于SAGA没有附带开箱即用的模拟系统,为了快速测试,我们将寻求添加一个简单的基于文本的模拟系统,但我们认为保持模拟系统本身与SAGA分离以保持模拟不可知性很重要。我们将寻找希望构建自己的模拟系统或将其与现有开源模拟器一起使用的人,并期望看到对Generative Agents论文之后出现的简单2D模拟的快速支持。
其他模拟将在游戏或强化学习场景中拥有代理。一些模拟参与RPG战斗,如本周进行的Neurips MMO挑战赛。我们很高兴在SAGA的基础上构建,但也很高兴看到社区如何使用它并做出贡献。查看GitHub仓库了解更多信息。
[AI] · [Simulations] · [Agents] · [Tool-Use]
[Previous Previous Thistle Gulch Simulation Beta Op…]
[Next Next SAGA Now Available: Open Source]
SAGA项目代码流程详细解析
1. SAGA核心架构与组件
SAGA框架的核心组件构成了一个层次化的架构,以实现AI代理行动生成的功能。
1.1 主要组件概述
SAGA的核心架构由以下几个主要组件构成:
- BaseSagaAgent: 所有代理的基类,提供了与语言模型交互的基础设施。
- ActionsAgent: 负责根据上下文和技能生成行动选项。
- ConversationAgent: 负责生成角色之间的对话。
- EmbeddingAgent: 负责生成文本嵌入,用于记忆检索和相似度匹配。
1.2 核心组件详解
下面是主要组件的关系图:
classDiagram
class BaseSagaAgent {
+prompt_template
+callback_handler
+_llm
+generate_chain()
}
class ActionsAgent {
+guidance
+generate_actions()
}
class ConversationAgent {
+generate_conversation()
}
class EmbeddingAgent {
+embed_documents()
+embed_query()
+store_documents()
+find_similar()
}
class Skill {
+name
+description
+parameters
}
class Action {
+skill
+parameters
}
class GeneratedActions {
+options
+scores
+raw_prompt
+raw_response
+llm_info
+sort()
}
BaseSagaAgent <|-- ActionsAgent
BaseSagaAgent <|-- ConversationAgent
ActionsAgent ..> Skill
ActionsAgent ..> GeneratedActions
GeneratedActions o-- Action
1.2.1 BaseSagaAgent
BaseSagaAgent是所有SAGA代理的基类,它提供了与语言模型交互的基础设施:
1 | def __init__(self, prompt_template: BasePromptTemplate, llm: Optional[BaseLanguageModel] = None): |
1.2.2 ActionsAgent
ActionsAgent继承自BaseSagaAgent,专门负责生成行动选项:
1 | def __init__(self, llm: Optional[BaseLanguageModel] = None): |
1.2.3 ConversationAgent
ConversationAgent也继承自BaseSagaAgent,专门用于生成角色之间的对话:
1 | def __init__(self, llm: Optional[BaseLanguageModel] = None): |
1.2.4 EmbeddingAgent
EmbeddingAgent负责生成文本嵌入并与向量数据库交互(更多细节见章节3):
1 | class EmbeddingAgent: |
1.3 关键数据结构
SAGA框架中使用的一些关键数据结构:
Skill: 代表代理可以执行的技能。
1
2
3
4# class Skill:
# +name
# +description
# +parametersAction: 代表一个被选定执行的具体技能和其参数。
1
2
3# class Action:
# +skill
# +parametersGeneratedActions: 包含由
ActionsAgent生成的行动选项列表及其相关信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class GeneratedActions:
options: List[Action]
scores: List[float]
raw_prompt: Optional[str] = None
raw_response: Optional[str] = None
llm_info: Optional[Dict[str, Any]] = None
retries: int = 0
error: Optional[str] = None
def sort(self):
"""按分数排序行动选项"""
self.options = [
x
for _, x in sorted(
zip(self.scores, self.options), key=lambda pair: pair[0], reverse=True
)
]
self.scores = sorted(self.scores, reverse=True)
2. 核心工作流程
SAGA的主要工作流程涉及环境交互、行动生成、行动执行、对话生成和记忆管理。
2.1 总体流程
SAGA的主要工作流程可以用以下流程图表示:
graph TD
A[模拟环境] -->|提供上下文和技能| B[ActionsAgent]
B -->|生成行动选项| C[行动选项]
C -->|选择执行| D[SimAction]
D -->|更新环境和记忆| A
A -->|提供对话角色和上下文| E[ConversationAgent]
E -->|生成对话| F[对话内容]
F -->|更新记忆| A
A -->|提供记忆查询| G[EmbeddingAgent]
G -->|检索相关记忆| A
2.2 详细执行流程概述
- 初始化阶段:
- 加载模拟环境(如Space Colony示例)。
- 初始化各种代理(
ActionsAgent,ConversationAgent等)。 - 加载技能定义、角色、位置等元数据。
- 行动生成流程:
- 模拟环境调用
ActionsAgent.generate_actions()。 - 该方法接收上下文(包含角色信息、记忆等)和可用技能列表。
- 构建提示(prompt),发送给LLM。
- LLM返回JSON格式的行动选项,每个选项包含一个技能名和参数。
- 将选项解析为
GeneratedActions对象并按分数排序。 - 返回排序后的行动选项供模拟环境使用。
- 模拟环境调用
- 行动执行流程:
- 模拟环境选择一个行动选项。
- 创建对应的
SimAction子类实例。 - 调用该实例的
tick()方法随时间推进行动。 - 行动完成时,更新角色的记忆和状态。
- 对话生成流程:
- 当角色需要交谈时,调用
ConversationAgent.generate_conversation()。 - 该方法接收参与对话的角色ID和上下文。
- 构建提示,发送给LLM。
- LLM返回JSON格式的对话内容。
- 将对话内容保存为角色的记忆。
- 当角色需要交谈时,调用
- 记忆检索流程:
- 使用
EmbeddingAgent将文本转换为向量嵌入。 - 存储记忆文档及其嵌入到向量数据库。
- 当需要相关记忆时,执行相似度搜索找出最相关的记忆。
- 使用
2.3 行动生成流程详解
SAGA的核心功能是生成行动选项。
2.3.1 详细流程图
下面是详细的行动生成流程:
sequenceDiagram
participant Client as 客户端/模拟环境
participant Agent as ActionsAgent
participant LLM as 语言模型
participant Parser as JSON解析器
Client->>Agent: 调用generate_actions(context, skills)
Agent->>Agent: 验证输入
Agent->>Agent: 构建Chain
Agent->>Agent: 将skills转换为JSON
Agent->>LLM: 发送提示和上下文
LLM->>Agent: 返回原始响应
Agent->>Parser: 解析JSON响应
Parser->>Agent: 返回解析后的结构
Agent->>Agent: 创建GeneratedActions对象
Agent->>Agent: 按分数排序行动选项
Agent->>Client: 返回GeneratedActions
2.3.2 提示模板设计
SAGA使用YAML格式的提示模板来构建发送给语言模型的提示。以下是行动生成的模板:
1 | _type: prompt |
2.3.3 行动解析和排序
行动选项从LLM返回后,由ActionsAgent解析JSON响应,并使用GeneratedActions对象的sort()方法(如1.3节所示)按分数对行动选项进行排序。
2.4 对话生成流程详解
当角色需要进行对话时,模拟环境会调用ConversationAgent的generate_conversation()方法。此方法(如1.2.3节代码所示)接收参与对话的角色ID列表和当前上下文。它会构建一个专门的提示发送给语言模型,LLM随后返回JSON格式的对话内容。这些对话内容被构造成GeneratedConversation对象,并可以被保存为角色的记忆。
2.5 完整的模拟执行流程
2.5.1 模拟环境中的用户交互驱动流程(以Space Colony示例)
sequenceDiagram
participant User
participant Simulation
participant ActionsAgent
participant LLM
participant SimAction
User->>Simulation: 运行示例
Simulation->>Simulation: 加载元数据
loop 每个角色
Simulation->>ActionsAgent: generate_action_options(agent)
ActionsAgent->>LLM: 发送上下文和技能
LLM->>ActionsAgent: 返回行动选项
ActionsAgent->>Simulation: 返回排序后的行动选项
Simulation->>User: 显示行动选项列表
User->>Simulation: 选择一个行动
Simulation->>SimAction: 创建行动实例
SimAction->>Simulation: 更新角色状态和记忆
end
2.5.2 SAGA内部行动生成到执行的详细流程
sequenceDiagram
participant Sim as 模拟系统
participant Agent as 模拟代理
participant Context as 上下文生成器
participant SAGA as SAGA框架 (ActionsAgent)
participant LLM as 语言模型
participant ActionFactory as 行动工厂
Sim->>Agent: tick(delta_time)
Alt 需要新行动
Agent->>Context: 请求生成上下文
Context->>Context: 收集代理信息、环境信息、记忆等
Context-->>Agent: 返回格式化上下文
Agent->>SAGA: generate_actions(context, skills)
SAGA->>LLM: 发送提示(context + skills)
LLM-->>SAGA: 返回JSON格式行动选项和评分
SAGA-->>Agent: 返回GeneratedActions对象
Agent->>Agent: 选择行动(通常是最高评分)
Agent->>ActionFactory: 创建行动实例 (e.g., sim_action_factory)
ActionFactory-->>Agent: 返回具体SimAction子类实例
Agent->>Agent: 设置当前action
End
Agent->>Agent: tick_action(delta_time) // 调用 SimAction.tick()
Agent->>Agent: 更新行动状态和运行时间
Alt 行动完成
Agent->>Agent: 添加记忆 (e.g., MemoryStore.append)
Agent->>Agent: action.complete()
Agent->>Agent: action = None
End
Agent-->>Sim: 返回控制
3. 记忆与嵌入机制
SAGA的记忆系统利用向量嵌入来存储和检索记忆,从而使代理能够根据过去的经验做出更明智的决策。
3.1 概述
SAGA的记忆和嵌入机制工作流程如下:
graph TD
A[文本记忆] -->|嵌入生成| B[向量嵌入]
B -->|存储| C[向量数据库]
D[查询] -->|嵌入生成| E[查询向量]
E -->|相似度搜索| C
C -->|相关记忆| F[检索结果]
3.2 EmbeddingAgent 的作用
EmbeddingAgent (详见1.2.4节) 在此机制中扮演核心角色。它负责:
- 将文本(如观察、对话、思考)转换为向量嵌入。
- 将这些嵌入及其原始文本(和元数据)存储到向量存储中。
- 当需要检索相关记忆时,将查询文本转换为查询向量,并在向量存储中执行相似度搜索。
3.3 SimpleVectorStore 实现
SimpleVectorStore是一个简单的内存向量存储实现,使用numpy进行相似度搜索。它是SAGA中用于演示和快速启动的默认向量存储。
1 | class SimpleVectorStore(VectorStore): |
3.4 记忆和元记忆处理
元记忆处理是SAGA框架的核心特点之一,它允许代理不仅存储事实,还存储关于其自身状态、目标和知识的结构化信息。
元记忆典型数据结构示例:
1 | { |
记忆处理流程:
- 模拟系统维护每个代理的记忆库(例如使用
MemoryStore,它可能内部使用EmbeddingAgent和VectorStore)。 - 新的行动结果、观察和对话被添加为记忆条目到记忆库中。
- 在为
ActionsAgent或ConversationAgent构建上下文时,系统会从记忆库中检索相关记忆。这通常涉及将当前情况或查询嵌入化,然后通过向量相似度搜索找到语义相关的记忆。 - 检索到的记忆被格式化并包含在提供给LLM的上下文中,以指导其生成行动或对话。
- 一些记忆系统可能会实现记忆的淡忘特性,使得较旧或较少访问的记忆随时间变得不那么突出或检索权重降低。
4. 模拟环境集成
SAGA提供了一个Space Colony示例,展示了如何将框架集成到模拟环境中。集成的关键在于将SAGA的代理(如ActionsAgent)与模拟世界中的代理(SimAgent)连接起来,并通过模拟行动(SimAction)来执行SAGA生成的决策。
4.1 模拟代理 (SimAgent)
SimAgent是模拟环境中的代理,它持有一个角色(persona)、位置、技能列表和当前正在执行的行动。它还拥有一个MemoryStore来存储其记忆。
1 |
|
4.2 模拟行动 (SimAction)
SimAction及其子类实现了代理可以执行的各种具体行动。每个SimAction子类对应一个SAGA Skill。当一个行动被选择后,其实例被创建,并且其tick()方法会在模拟的每个时间步被调用,直到行动完成。
1 | class SimAction: |
4.3 行动生成器 (ActionGenerator)
ActionGenerator是模拟环境中的一个辅助类,它封装了与SAGA ActionsAgent的交互,以便为SimAgent生成行动选项。它还包含一个工厂方法 (sim_action_factory),用于将SAGA返回的抽象Action数据转换为具体的SimAction子类实例。
1 | class ActionGenerator: |
5. 服务器实现
SAGA可以作为服务器运行,通过HTTP、WebSocket或SocketIO等协议提供接口,使得非Python或其他外部模拟环境也能利用SAGA的AI代理能力。
5.1 架构概述
SAGA服务器架构允许外部客户端与核心SAGA代理进行交互:
graph TD
A[客户端] -->|请求| B{服务器类型}
B -->|HTTP| C[HTTP处理器]
B -->|WebSocket| D[WebSocket处理器]
B -->|SocketIO| E[SocketIO处理器]
C -->|处理请求| F[端点]
D -->|处理请求| F
E -->|处理请求| F
F -->|ActionsEndpoint| G[ActionsAgent]
F -->|ConversationEndpoint| H[ConversationAgent]
F -->|EmbeddingsEndpoint| I[EmbeddingAgent]
G -->|返回行动| F
H -->|返回对话| F
I -->|返回嵌入| F
F -->|构建响应| C
F -->|构建响应| D
F -->|构建响应| E
C -->|响应| A
D -->|响应| A
E -->|响应| A
5.2 端点设计
SAGA的服务器使用统一的端点设计模式,每个端点负责处理特定类型的请求并与相应的SAGA代理交互。
1 | class BaseEndpoint(Generic[TReq, TResp]): |
5.3 HTTP服务器
HTTP服务器通常使用像aiohttp这样的异步Web框架实现。请求被路由到相应的端点处理器。
1 |
|
5.4 WebSocket和SocketIO
WebSocket和SocketIO接口为需要实时、双向通信的客户端提供支持。它们允许服务器在生成结果后主动将结果推送给客户端。
1 |
|